MultiStepLR#
- class torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1)[source]#
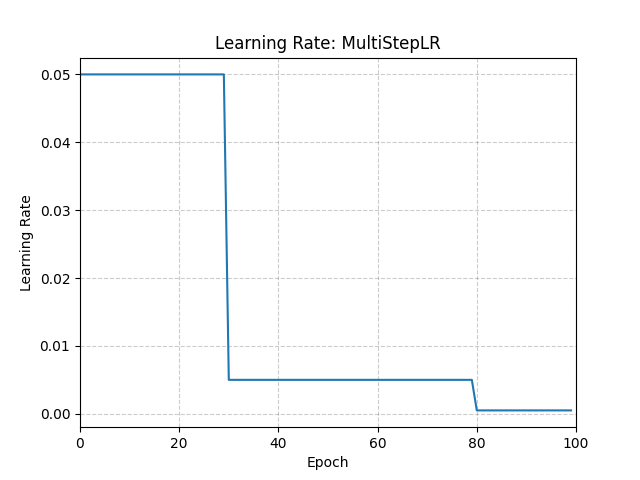
Decays the learning rate of each parameter group by gamma once the number of epoch reaches one of the milestones.
Notice that such decay can happen simultaneously with other changes to the learning rate from outside this scheduler. When last_epoch=-1, sets initial lr as lr.
- Parameters:
Example
>>> # Assuming optimizer uses lr = 0.05 for all groups >>> # lr = 0.05 if epoch < 30 >>> # lr = 0.005 if 30 <= epoch < 80 >>> # lr = 0.0005 if epoch >= 80 >>> scheduler = MultiStepLR(optimizer, milestones=[30, 80], gamma=0.1) >>> for epoch in range(100): >>> train(...) >>> validate(...) >>> scheduler.step()
- get_last_lr()[source]#
Get the most recent learning rates computed by this scheduler.
- Returns:
A
listof learning rates with entries for each of the optimizer’sparam_groups, with the same types as theirgroup["lr"]s.- Return type:
Note
The returned
Tensors are copies, and never alias the optimizer’sgroup["lr"]s.
- get_lr()[source]#
Compute the next learning rate for each of the optimizer’s
param_groups.If the current epoch is in
milestones, decays thegroup["lr"]s in the optimizer’sparam_groupsbygamma.- Returns:
A
listof learning rates for each of the optimizer’sparam_groupswith the same types as their currentgroup["lr"]s.- Return type:
Note
If you’re trying to inspect the most recent learning rate, use
get_last_lr()instead.Note
The returned
Tensors are copies, and never alias the optimizer’sgroup["lr"]s.Note
If the current epoch appears in
milestonesntimes, we scale bygammato the power ofn
- load_state_dict(state_dict)[source]#
Load the scheduler’s state.
- Parameters:
state_dict (dict) – scheduler state. Should be an object returned from a call to
state_dict().
- state_dict()[source]#
Return the state of the scheduler as a
dict.It contains an entry for every variable in
self.__dict__which is not the optimizer.
- step(epoch=None)[source]#
Step the scheduler.
- Parameters:
epoch (int, optional) –
Deprecated since version 1.4: If provided, sets
last_epochtoepochand uses_get_closed_form_lr()if it is available. This is not universally supported. Usestep()without arguments instead.
Note
Call this method after calling the optimizer’s
step().