Draft Export#
Created On: Jun 13, 2025 | Last Updated On: Jun 13, 2025
Warning
This feature is not meant to be used in production and is designed to be used as a tool for debugging torch.export tracing errors.
Draft-export is a new version of export, which is designed to consistently produce a graph, even if there are potential soundness issues, and to generate a report listing out all of the issues export encountered during tracing and providing additional debugging information. For custom operators that don’t have fake kernels, it will also generate a profile which you can register to automatically generate a fake kernel.
Have you ever tried to export a model using torch.export.export(), only to
encounter a data-dependent issue? You fix it, but then run into a missing fake
kernel problem. And after resolving that, you get hit with another
data-dependent issue. You wonder to yourself, I wish there was a way I could
just get a graph to play around with, and be able to view all the issues in one
place so that I can fix them later…
draft_export to the rescue!
draft_export is a version of export which will always successfully export a
graph, even if there are potential soundness issues. These issues will then be
compiled into a report for clearer visualization, which can be fixed later on.
What sort of errors does it catch?#
Draft-export helps to catch and debug the following errors:
Guard on data-dependent errors
Constraint violation errors
Missing fake kernels
Incorrectly written fake kernels
How does it work?#
In normal export, we will convert the sample inputs into FakeTensors and use
them to record operations and trace the program into a graph. Input tensor
shapes that can change (which are marked through dynamic_shapes), or values
within tensors (typically from an .item() call) will be represented as a symbolic
shape (SymInt) instead of a concrete integer. However some issues may occur
while tracing - we may run into guards that we cannot evaluate, like if we want
to check if some item in a tensor is greater than 0 (u0 >= 0). Since the tracer
doesn’t know anything about the value of u0, it will throw a data-dependent
error. If the model uses a custom operator but a fake kernel hasn’t been
defined for it, then we will error with fake_tensor.UnsupportedOperatorException
because export doesn’t know how to apply this on FakeTensors. If a custom
operator has a fake kernel implemented incorrectly, export will silently produce
an incorrect graph that doesn’t match the eager behavior.
To fix the above errors, draft-export uses real tensor tracing to guide us on
how to proceed when tracing. As we trace the model with fake tensors, for every
operation that happens on a fake tensor, draft-export will also run the operator
on stored real tensors which come from the example inputs passed to export. This
allows us to address the above errors: When we reach a guard that we cannot
evaluate, like u0 >= 0, we will use the stored real tensor values to
evaluate this guard. Runtime asserts will be added into the graph to ensure that
the graph asserts the same guard that we assumed while tracing. If we run into
a custom operator without a fake kernel, we will run the operator’s normal
kernel with the stored real tensors, and return a fake tensor with the same rank
but unbacked shapes. Since we have the real tensor output for every operation,
we will compare this with the fake tensor output from the fake kernel. If the
fake kernel is implemented incorrectly, we will then catch this behavior and
generate a more correct fake kernel.
How can I use draft export?#
Let’s say you’re trying to export this piece of code:
class M(torch.nn.Module):
def forward(self, x, y, z):
res = torch.ops.mylib.foo2(x, y)
a = res.item()
a = -a
a = a // 3
a = a + 5
z = torch.cat([z, z])
torch._check_is_size(a)
torch._check(a < z.shape[0])
return z[:a]
inp = (torch.tensor(3), torch.tensor(4), torch.ones(3, 3))
ep = torch.export.export(M(), inp)
This runs into a “missing fake kernel” error for mylib.foo2 and then a
GuardOnDataDependentExpression because of the slicing of z with a,
an unbacked symint.
To call draft-export, we can replace the torch.export line with the following:
ep = torch.export.draft_export(M(), inp)
ep is a valid ExportedProgram which can now be passed through further environments!
Debugging with draft-export#
In the terminal output from draft-export, you should see the following message:
#########################################################################################
WARNING: 2 issue(s) found during export, and it was not able to soundly produce a graph.
To view the report of failures in an html page, please run the command:
`tlparse /tmp/export_angelayi/dedicated_log_torch_trace_axpofwe2.log --export`
Or, you can view the errors in python by inspecting `print(ep._report)`.
########################################################################################
Draft-export automatically dumps logs for tlparse. You can view the tracing
errors by using print(ep._report), or you can pass the logs into tlparse
to generate an html report.
Running the tlparse command in the terminal will generate a
tlparse
HTML report. Here is an example of the tlparse report:

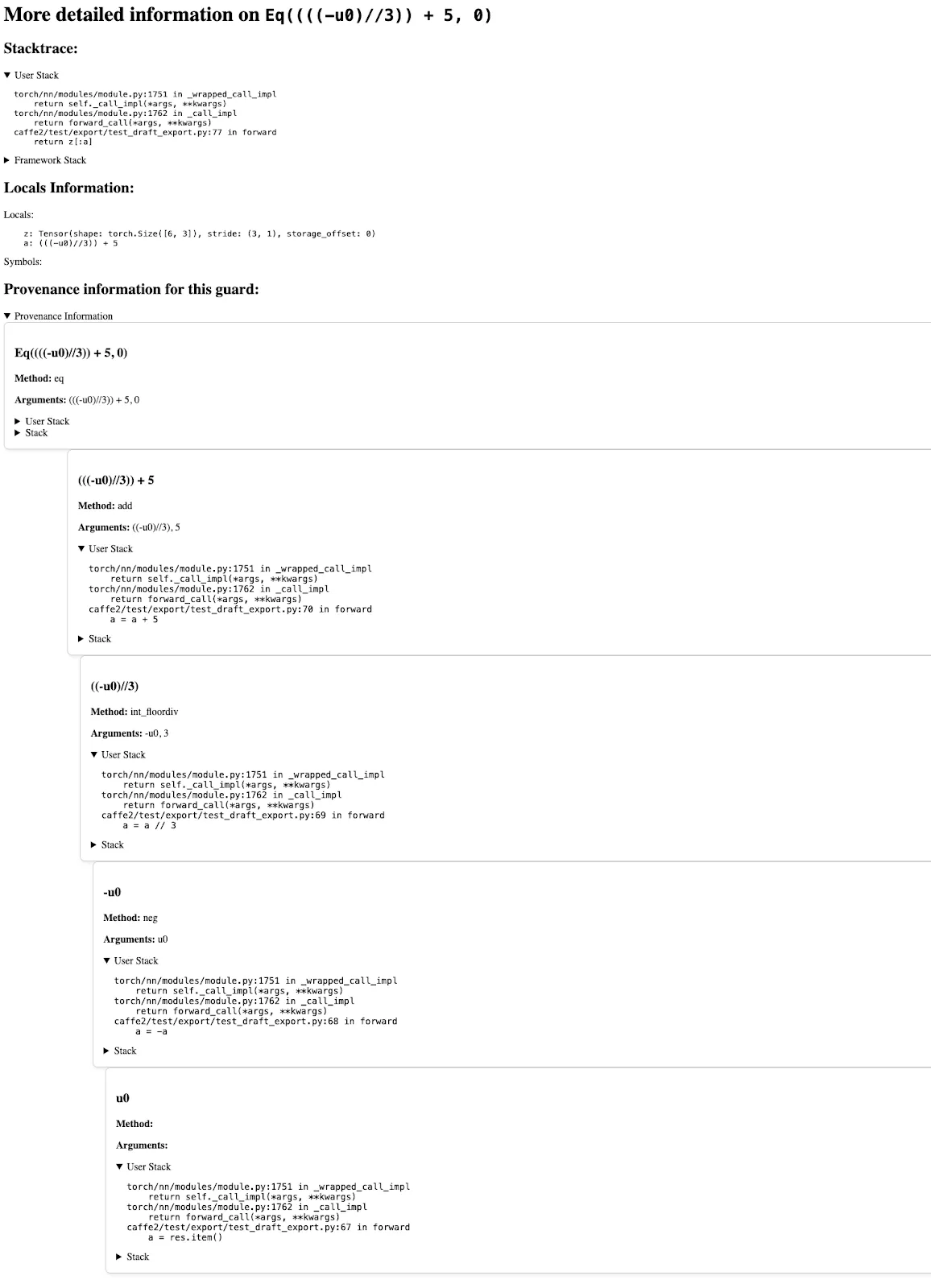
Clicking into the Data Dependent Error, we will see the following page which contains information to help debug this error. Specifically, it contains:
The stacktrace at which this error occurs
A list of local variables and their shapes
Information for how this guard was created
The returned Exported Program#
Because draft-export specializes on code paths based on the example inputs, the exported program resulting from draft-export is guaranteed to be runnable and return correct results for at least the given example inputs. Other inputs can work, as long as they match the same guards that were taken when we were draft-exporting.
For example, if we have a graph branching on if a value is greater than 5, if in
draft-export our example inputs were greater than 5, then the returned
ExportedProgram will specialize on that branch, and will assert that the value
is greater than 5. This means that the program will succeed if you pass in
another value greater than 5, but will fail if you pass in a value less than 5.
This is more sound than torch.jit.trace, which will silently specialize on the
branch. The proper way for torch.export to support both branches would be to
rewrite the code using torch.cond, which will then capture both branches.
Because of the runtime assertions in the graph, the returned exported-program is
also retraceable with torch.export or torch.compile, with a minor addition in
the case where a custom operator is missing a fake kernel.
Generating Fake Kernels#
If a custom operator does not contain a fake implementation, currently draft-export will use the real-tensor propagation to get an output for the operator and continue tracing. However, if we run the exported program with fake tensors or retrace the exported model, we will still fail because there is still no fake kernel implementation.
To address this, after draft-export, we will generate an operator profile for
each custom operator call that we encounter, and store this on the report
attached to the exported program: ep._report.op_profiles. Users can then use the
context manager torch._library.fake_profile.unsafe_generate_fake_kernels to
generate and register a fake implementation based on these operator profiles.
This way future fake tensor retracing will work.
The workflow would look something like:
class M(torch.nn.Module):
def forward(self, a, b):
res = torch.ops.mylib.foo(a, b) # no fake impl
return res
ep = draft_export(M(), (torch.ones(3, 4), torch.ones(3, 4)))
with torch._library.fake_profile.unsafe_generate_fake_kernels(ep._report.op_profiles):
decomp = ep.run_decompositions()
new_inp = (
torch.ones(2, 3, 4),
torch.ones(2, 3, 4),
)
# Save the profile to a yaml and check it into a codebase
save_op_profiles(ep._report.op_profiles, "op_profile.yaml")
# Load the yaml
loaded_op_profile = load_op_profiles("op_profile.yaml")
The operator profile is a dictionary mapping operator name to a set of profiles
which describe the input and outputs of the operator, and could be manually
written, saved into a yaml file, and checked into a codebase. Here’s an example
of a profile for mylib.foo.default:
"mylib.foo.default": {
OpProfile(
args_profile=(
TensorMetadata(
rank=2,
dtype=torch.float32,
device=torch.device("cpu"),
layout=torch.strided,
),
TensorMetadata(
rank=2,
dtype=torch.float32,
device=torch.device("cpu"),
layout=torch.strided,
),
),
out_profile=TensorMetadata(
rank=2,
dtype=torch.float32,
device=torch.device("cpu"),
layout=torch.strided,
),
)
}
mylib.foo.default’s profile contains only one profile, which says that for 2
input tensors of rank 2, dtype torch.float32, device cpu, we will return
one tensor of rank 2, dtype torch.float32, and device cpu. Using the
context manager, will then generate a fake kernel where given 2 input tensors of
rank 2 (and the other tensor metadata), we will output one tensor of rank 2 (and
the other tensor metadata).
If the operator also supports other input ranks, then we can add the profile to this list of profiles, either by manually adding it into the existing profile or rerunning draft-export with new inputs to get new profiles, so that the generated fake kernel will support more input types. Otherwise it will error.
Where to go from here?#
Now that we have successfully created an ExportedProgram using draft-export,
we can use further compilers such as AOTInductor to optimize its performance
and produce a runnable artifact. This optimized version can then be used for
deployment. In parallel, we can utilize the report generated by draft-export to
identify and fix torch.export errors that were encountered so that the
original model can be directly traceable with torch.export.