Saving TensorDict and tensorclass objects¶
While we can just save a tensordict with save(), this
will create a single file with the whole content of the data structure.
One can easily imagine situations where this is sub-optimal!
TensorDict serialization API mainly relies on MemoryMappedTensor
which is used to write tensors independently on disk with a data structure
that mimics the TensorDict’s one.
TensorDict’s serialization speed can be an order of magnitude faster than
PyTorch’s one with save()’s pickle reliance. This document explains
how to create and interact with data stored on disk using TensorDict.
Saving memory-mapped TensorDicts¶
When a tensordict is dumped as a mmap data structure, each entry corresponds
to a single *.memmap file, and the directory structure is determined by the
key structure: generally, nested keys correspond to sub-directories.
Saving a data structure as a structured set of memory-mapped tensors has the following advantages:
The saved data can be partially loaded. If a large model is saved on disk but only parts of its weights need to be loaded onto a module created in a separate script, only these weights will be loaded in memory.
Saving data is safe: using the pickle library for serializing big data structures can be unsafe as unpickling can execute any arbitrary code. TensorDict’s loading API only reads pre-selected fields from saved json files and memory buffers saved on disk.
Saving is fast: because the data is written in several independent files, we can amortize the IO overhead by launching several concurrent threads that each access a dedicated file on their own.
The structure of the saved data is apparent: the directory tree is indicative of the data content.
However, this approach also has some disadvantages:
Not every data type can be saved.
tensorclassallows to save any non-tensor data: if these data can be represented in a json file, a json format will be used. Otherwise, non-tensor data will be saved independently withsave()as a fallback. TheNonTensorDataclass can be used to represent non-tensor data in a regularTensorDictinstance.
tensordict’s memory-mapped API relies on four core methods:
memmap_(), memmap(),
memmap_like() and load_memmap().
The memmap_() and memmap()
methods will write the data on disk with or without modifying the tensordict
instance that contains the data. These methods can be used to serialize a model
on disk (we use multiple threads to speed up serialization):
>>> model = nn.Transformer()
>>> weights = TensorDict.from_module(model)
>>> weights_disk = weights.memmap("/path/to/saved/dir", num_threads=32)
>>> new_weights = TensorDict.load_memmap("/path/to/saved/dir")
>>> assert (weights_disk == new_weights).all()
The memmap_like() is to be used when a dataset
needs to be preallocated on disk, the typical usage being:
>>> def make_datum(): # used for illustration purposes
... return TensorDict({"image": torch.randint(255, (3, 64, 64)), "label": 0}, batch_size=[])
>>> dataset_size = 1_000_000
>>> datum = make_datum() # creates a single instance of a TensorDict datapoint
>>> data = datum.expand(dataset_size) # does NOT require more memory usage than datum, since it's only a view on datum!
>>> data_disk = data.memmap_like("/path/to/data") # creates the two memory-mapped tensors on disk
>>> del data # data is not needed anymore
As illustrated above, when converting entries of a TensorDict
to MemoryMappedTensor, it is possible to control where
the memory maps are saved on disk so that they persist and can
be loaded at a later date. On the other hand, the file system can also be used.
To use this, simply discard the prefix argument in the three serialization
methods above.
When a prefix is specified, the data structure follows the TensorDict’s one:
>>> import torch
>>> from tensordict import TensorDict
>>> td = TensorDict({"a": torch.rand(10), "b": {"c": torch.rand(10)}}, [10])
>>> td.memmap_(prefix="tensordict")
yields the following directory structure
tensordict
├── a.memmap
├── b
│ ├── c.memmap
│ └── meta.json
└── meta.json
The meta.json files contain all the relevant information to rebuild the
tensordict, such as device, batch-size, but also the tensordict subtypes.
This means that load_memmap() will be able to
reconstruct complex nested structures where sub-tensordicts have different types
than parents:
>>> from tensordict import TensorDict, tensorclass, TensorDictBase
>>> from tensordict.utils import print_directory_tree
>>> import torch
>>> import tempfile
>>> td_list = [TensorDict({"item": i}, batch_size=[]) for i in range(4)]
>>> @tensorclass
... class MyClass:
... data: torch.Tensor
... metadata: str
>>> tc = MyClass(torch.randn(3), metadata="some text", batch_size=[])
>>> data = TensorDict({"td_list": torch.stack(td_list), "tensorclass": tc}, [])
>>> with tempfile.TemporaryDirectory() as tempdir:
... data.memmap_(tempdir)
...
... loaded_data = TensorDictBase.load_memmap(tempdir)
... assert (loaded_data == data).all()
... print_directory_tree(tempdir)
tmpzy1jcaoq/
tensorclass/
_tensordict/
data.memmap
meta.json
meta.json
td_list/
0/
item.memmap
meta.json
1/
item.memmap
meta.json
3/
item.memmap
meta.json
2/
item.memmap
meta.json
meta.json
meta.json
Handling existing MemoryMappedTensor¶
If the TensorDict already contains
MemoryMappedTensor entries there are a few
possible behaviours.
If
prefixis not specified andmemmap()is called twice, the resulting TensorDict will contain the same data as the original one.>>> td = TensorDict({"a": 1}, []) >>> td0 = td.memmap() >>> td1 = td0.memmap() >>> td0["a"] is td1["a"] True
If
prefixis specified and differs from the prefix of the existingMemoryMappedTensorinstances, an exception is raised, unless copy_existing=True is passed:>>> with tempfile.TemporaryDirectory() as tmpdir_0: ... td0 = td.memmap(tmpdir_0) ... td0 = td.memmap(tmpdir_0) # works, results are just overwritten ... with tempfile.TemporaryDirectory() as tmpdir_1: ... td1 = td0.memmap(tmpdir_1) ... td_load = TensorDict.load_memmap(tmpdir_1) # works! ... assert (td_load == td).all() ... with tempfile.TemporaryDirectory() as tmpdir_1: ... td_load = TensorDict.load_memmap(tmpdir_1) # breaks!
This feature is implemented to prevent users from inadvertently copying memory-mapped tensors from one location to another.
Single-file memmap archives¶
A memory-mapped directory is convenient to work with locally, but shipping it
around means copying many small files. Passing a path ending in ".tdz"
(or archive=True) to save(),
dumps() or
memmap() writes the exact same data layout
as a single file instead:
>>> td = TensorDict({"a": torch.rand(10), "b": {"c": torch.rand(10)}}, [10])
>>> td.save("data.tdz")
>>> td2 = TensorDict.load_memmap("data.tdz")
>>> assert (td == td2).all()
The archive is a standard zip file whose entries replicate the memmap
directory tree (meta.json files and *.memmap payloads). Tensor
payloads are stored uncompressed and aligned, so
load_memmap() memory-maps the archive once
and exposes every leaf as a zero-copy view into the mapping: metadata aside,
nothing is read from disk until a tensor is actually accessed. Because the
entry tree is the directory tree, the two representations are freely
convertible – with pack_memmap() /
unpack_memmap(), or with any zip tool:
unzip data.tdz -d data_dir # yields a loadable memmap directory
(cd data_dir && zip -0 -r ../data.zip .) # yields a loadable archive
Partial loading works as with directories: the subpath argument of
load_memmap() selects a nested tensordict
without touching the rest of the archive:
>>> sub = TensorDict.load_memmap("model.tdz", subpath="encoder/layers")
Archives can optionally be compressed (compression="deflate" among
others). Compressed leaves cannot be memory-mapped and are decompressed in
memory on first access, so this is a trade-off reserved for archival storage;
data such as uint8 images or boolean masks compress well, whereas float
weights barely do.
Note
Two differences with directory-backed tensordicts are worth keeping in
mind. First, by default an archive-loaded tensordict behaves like the
result of from_consolidated(): leaves are
views into a single storage and in-place writes do not propagate to
the file. Second, archives written by external zip tools (without payload
alignment) load correctly, but misaligned leaves are copied in memory
rather than viewed.
Write-through loading is available as an explicit opt-in with
mode="r+", restoring the directory semantics for a single file:
>>> td = TensorDict.load_memmap("data.tdz", mode="r+")
>>> td["a"].add_(1) # written to the archive
The preallocation workflow of memmap_like()
works with archives as well: pointing it at a ".tdz" path creates a
zero-filled archive and returns a write-through tensordict backed by it,
i.e. a dataset buffer that lives in a single file:
>>> data = datum.expand(1_000_000)
>>> buffer = data.memmap_like("/path/to/data.tdz")
>>> buffer[0] = datum # written to the archive
In-place writes leave the per-entry CRC-32 checksums of the zip format
stale. load_memmap() never verifies
checksums, so this is harmless within tensordict, but call
refresh_archive_checksums() before handing a modified
archive to tools that do verify them (unzip,
unpack_memmap(), …).
How do the three on-disk representations (memmap directory, consolidated
file, archive) compare speed-wise, including against torch.save,
safetensors and zarr? The tensordict formats, torch.save and
safetensors all load lazily through mmap, so bulk read throughput is
essentially identical; the differences are in the per-entry overheads.
Opening scales with the number of entries and favors the single-file
formats (one metadata parse instead of one file open per leaf). Saving an
archive streams the tensor bytes into the file in a single pass and is
comparable to a directory save, with a per-entry overhead that shows for
many-small-leaf layouts. Copying the saved artifact is where single files
shine: a directory pays per-file latency, which dominates for
many-small-leaf layouts on local disk and grows with round-trip time on
network filesystems. Note that torch.save and safetensors are measured
on their fastest paths (flat tensor dicts, torch.load(mmap=True,
weights_only=True) and mmap-backed loading respectively) and do not
represent tensordict structure natively: keys are flattened at save time
and the nesting rebuilt at load time. zarr
(to_zarr() /
from_zarr(), see Storing large heterogeneous data) also
opens lazily but does not memory-map its payload, so bulk reads pay a
copy, and each array is a store round-trip, which shows on
many-tiny-leaf layouts; its strengths are elsewhere – chunking,
compression and object-store backends.
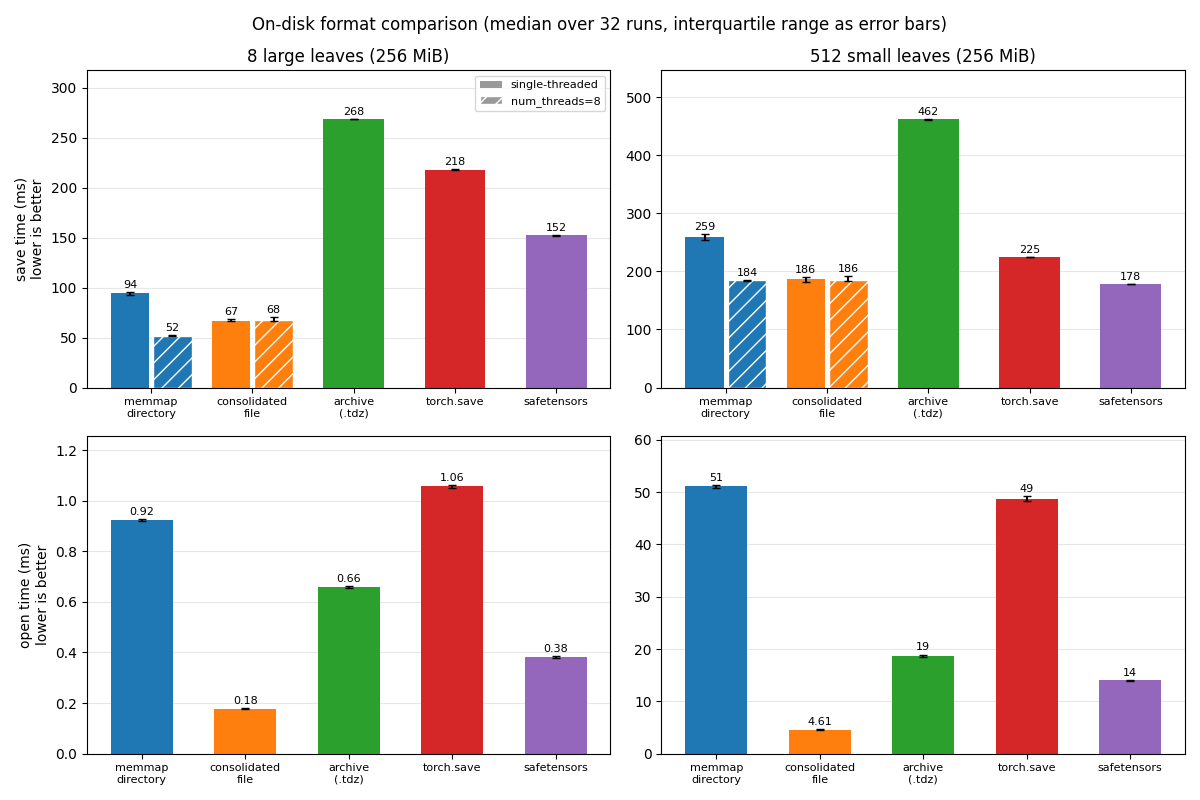
Serialization timings across formats and layouts (lower is better;
median over 32 runs printed above each bar, interquartile range as
error bars; hatched bars are multithreaded saves). The figure is
generated on the machine that builds this documentation – click it to
open the corresponding tutorial and download the script. For a larger
offline run (bigger payloads, more layouts, read and copy timings),
see benchmarks/scripts/serialization_formats_bench.py.¶
Consolidated serialization¶
For fast transfer (e.g. across the network, or to GPU), you can consolidate all
leaf tensors into a single contiguous buffer using
consolidate():
>>> td = TensorDict(a=torch.randn(1000), b={"c": torch.randn(1000)}, batch_size=[1000])
>>> td_c = td.consolidate()
A consolidated tensordict can be pickled much faster than a regular one because it becomes a single storage + metadata dict. It can also be saved to disk as a memory-mapped file:
>>> td_c = td.consolidate("/path/to/storage.memmap")
See consolidate() for the full API, including
options like num_threads, device, pin_memory, and share_memory.
Serialization speed¶
The figure below compares the speed of the main serialization paths (in-memory consolidation, consolidation to a memory-mapped file, and per-leaf directory save), single-threaded and multithreaded, on a payload made of a few large leaves and one made of many small leaves. It is generated when this documentation is built, so it reflects the machine that built these docs; each bar is an average over several runs.
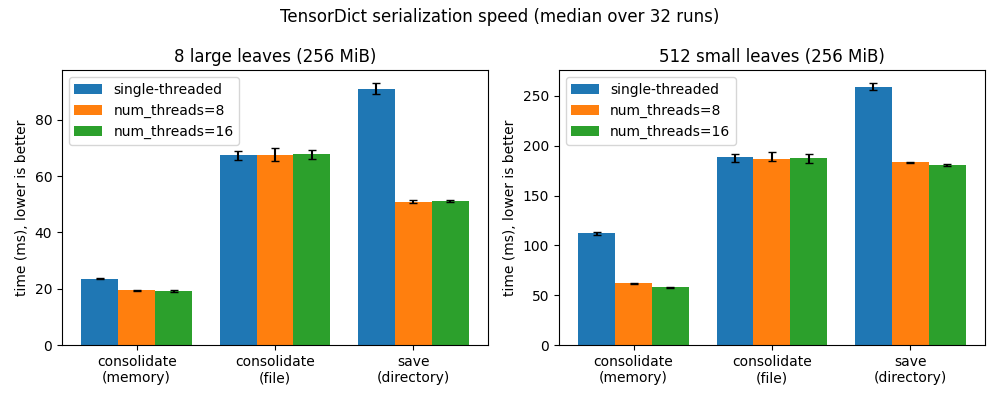
TensorDict serialization speed. Click the figure to open the corresponding tutorial.¶
To measure your own hardware, download the script from the
serialization speed tutorial
(or run python tutorials/sphinx_tuto/serialization_speed.py from a
tensordict checkout) — it only needs matplotlib on top of tensordict.
state_dict / load_state_dict¶
TensorDict and tensorclass support state_dict() and
load_state_dict(), following the same conventions as
torch.nn.Module.state_dict().
By default, state_dict() returns a flat OrderedDict with
dot-separated keys, just like nn.Module:
>>> td = TensorDict({"a": 1, "b": {"c": 2}}, [])
>>> sd = td.state_dict()
>>> print(sd)
OrderedDict([('a', tensor(1)), ('b.c', tensor(2))])
Metadata (batch_size, device) is stored in an _metadata attribute on the
returned OrderedDict, keyed by dot-separated prefix ("" for root, "b" for a
nested tensordict at key "b"). This mirrors nn.Module’s metadata convention
and replaces the legacy __batch_size / __device sentinel keys.
A nested format can be obtained by passing flatten=False:
>>> sd_nested = td.state_dict(flatten=False)
>>> print(sd_nested)
OrderedDict([('a', tensor(1)), ('b', OrderedDict([('c', tensor(2))]))])
load_state_dict() auto-detects the format of the
incoming state-dict: flat (with _metadata and dot-separated keys), nested (with
per-level _metadata), and the legacy format (with __batch_size / __device
sentinel keys) are all supported transparently:
>>> td_zero = td.clone().zero_()
>>> td_zero.load_state_dict(sd) # flat format
>>> assert (td_zero == td).all()
>>> td_zero.zero_()
>>> td_zero.load_state_dict(sd_nested) # nested format
>>> assert (td_zero == td).all()
For tensorclass objects, state_dict() exposes the logical field names as keys.
Non-tensor fields are stored in _metadata rather than appearing as data keys:
>>> @tensorclass
... class MyClass:
... x: torch.Tensor
... label: str
>>> tc = MyClass(x=torch.randn(3), label="hello", batch_size=[])
>>> sd = tc.state_dict()
>>> print(list(sd.keys())) # only tensor fields
['x']
>>> print(sd._metadata[""]["_non_tensor"]) # non-tensor fields
{'label': 'hello'}
Legacy: TorchSnapshot compatibility¶
Warning
torchsnapshot maintenance has been discontinued. The section below is kept for reference only; we recommend using the memory-mapped API above for new projects.
TensorDict is compatible with torchsnapshot. TorchSnapshot saves each tensor independently, with a data structure that mimics the TensorDict’s one.
In-memory loading
>>> import uuid
>>> import torchsnapshot
>>> from tensordict import TensorDict
>>> import torch
>>>
>>> tensordict_source = TensorDict({"a": torch.randn(3), "b": {"c": torch.randn(3)}}, [])
>>> state = {"state": tensordict_source}
>>> path = f"/tmp/{uuid.uuid4()}"
>>> snapshot = torchsnapshot.Snapshot.take(app_state=state, path=path)
>>> # later
>>> snapshot = torchsnapshot.Snapshot(path=path)
>>> tensordict_target = TensorDict()
>>> target_state = {"state": tensordict_target}
>>> snapshot.restore(app_state=target_state)
>>> assert (tensordict_source == tensordict_target).all()
Big-dataset loading (memory-mapped)
>>> td = TensorDict({"a": torch.randn(3), "b": TensorDict({"c": torch.randn(3, 1)}, [3, 1])}, [3])
>>> td.memmap_()
>>> assert isinstance(td["b", "c"], MemoryMappedTensor)
>>>
>>> app_state = {
... "state": torchsnapshot.StateDict(tensordict=td.state_dict(keep_vars=True))
... }
>>> snapshot = torchsnapshot.Snapshot.take(app_state=app_state, path=f"/tmp/{uuid.uuid4()}")
>>>
>>> td_dest = TensorDict({"a": torch.zeros(3), "b": TensorDict({"c": torch.zeros(3, 1)}, [3, 1])}, [3])
>>> td_dest.memmap_()
>>> assert isinstance(td_dest["b", "c"], MemoryMappedTensor)
>>> app_state = {
... "state": torchsnapshot.StateDict(tensordict=td_dest.state_dict(keep_vars=True))
... }
>>> snapshot.restore(app_state=app_state)
>>> assert (td_dest == td).all()
>>> assert (td_dest["b"].batch_size == td["b"].batch_size)
>>> assert isinstance(td_dest["b", "c"], MemoryMappedTensor)
