Arm® Ethos™-U NPU Backend#
The Arm® Ethos™-U backend targets Edge/IoT-type AI use-cases by enabling optimal execution of quantized models on Arm® Ethos™-U55 NPU, Arm® Ethos™-U65 NPU, and Arm® Ethos™-U85 NPU, leveraging TOSA and the ethos-u-vela graph compiler. This document is a technical reference for using the Ethos-U backend, for a top level view with code examples please refer to the Arm Ethos-U Backend Tutorial.
Features#
Wide operator support for delegating large parts of models to highly optimized and low power Ethos-U NPUs.
A quantizer that optimizes quantization for the NPU target.
Example runtime integration for easy hardware bringup.
Target Requirements#
The target system must include an Ethos-U NPU.
Development Requirements#
Tip
All requirements can be downloaded using examples/arm/setup.sh --i-agree-to-the-contained-eula and added to the path using
set(CMAKE_INSTALL_PREFIX “${CMAKE_BINARY_DIR}”)
source examples/arm/ethos-u-scratch/setup_path.sh. Note that this means accepting the End-User License Agreements (EULA:s) required for using the downloaded software.
For the AOT flow, compilation of a model to .pte format using the Ethos-U backend, the requirements are:
TOSA Serialization Library for serializing the Exir IR graph into TOSA IR.
Ethos-U Vela graph compiler for compiling TOSA flatbuffers into an Ethos-U command stream.
And for building and running the example application available in examples/arm/executor_runner/:
Arm GNU Toolchain for cross compilation.
Arm® Corstone™ SSE-300 FVP for testing on a Arm® Cortex®-M55+Ethos-U55 reference design.
Arm® Corstone™ SSE-320 FVP for testing on a Arm® Cortex®-M85+Ethos-U85 reference design.
Fixed Virtual Platforms (FVPs) are freely available emulators provided by Arm for easy embedded development without the need for a physical development board.
Using the Arm Ethos-U backend#
The main configuration point for the lowering is the EthosUCompileSpec consumed by the partitioner and quantizer.
The full user-facing API is documented below.
class EthosUCompileSpec(target: str, system_config: str | None = None, memory_mode: str | None = None, extra_flags: list[str] | None = None, config_ini: str | None = 'Arm/vela.ini')
Compile spec for Ethos-U NPU
Attributes:
target: Ethos-U accelerator configuration, e.g. ethos-u55-128.
system_config: System configuration to select from the Vela configuration file.
memory_mode: Memory mode to select from the Vela configuration file.
extra_flags: Extra flags for the Vela compiler.
config_ini: Vela configuration file(s) in Python ConfigParser .ini file format.
def EthosUCompileSpec.dump_debug_info(self, debug_mode: executorch.backends.arm.common.arm_compile_spec.ArmCompileSpec.DebugMode | None):
Dump debugging information into the intermediates path.
def EthosUCompileSpec.dump_intermediate_artifacts_to(self, output_path: str | None):
Sets a path for dumping intermediate results during lowering such as tosa and pte.
def EthosUCompileSpec.get_intermediate_path(self) -> str | None:
Returns the path for dumping intermediate results during lowering such as tosa and pte.
def EthosUCompileSpec.get_output_format() -> str:
Returns a constant string that is the output format of the class.
Partitioner API#
class EthosUPartitioner(compile_spec: executorch.backends.arm.ethosu.compile_spec.EthosUCompileSpec, additional_checks: Optional[Sequence[torch.fx.passes.operator_support.OperatorSupportBase]] = None) -> None
Partitions subgraphs supported by the Arm Ethos-U backend.
Attributes:
compile_spec: List of CompileSpec objects for Ethos-U backend.
additional_checks: Optional sequence of additional operator support checks.
def EthosUPartitioner.ops_to_not_decompose(self, ep: torch.export.exported_program.ExportedProgram) -> Tuple[List[torch._ops.OpOverload], Optional[Callable[[torch.fx.node.Node], bool]]]:
Returns a list of operator names that should not be decomposed. When these ops are
registered and the to_backend is invoked through to_edge_transform_and_lower it will be
guaranteed that the program that the backend receives will not have any of these ops
decomposed.
Returns:
List[torch._ops.OpOverload]: a list of operator names that should not be decomposed.
Optional[Callable[[torch.fx.Node], bool]]]: an optional callable, acting as a filter, that users can provide which will be called for each node in the graph that users can use as a filter for certain nodes that should be continued to be decomposed even though the op they correspond to is in the list returned by ops_to_not_decompose.
def EthosUPartitioner.partition(self, exported_program: torch.export.exported_program.ExportedProgram) -> executorch.exir.backend.partitioner.PartitionResult:
Returns the input exported program with newly created sub-Modules encapsulating specific portions of the input “tagged” for delegation.
The specific implementation is free to decide how existing computation in the input exported program should be delegated to one or even more than one specific backends.
The contract is stringent in that:
Each node that is intended to be delegated must be tagged
No change in the original input exported program (ExportedProgram) representation can take place other than adding sub-Modules for encapsulating existing portions of the input exported program and the associated metadata for tagging.
Args:
exported_program: An ExportedProgram in Edge dialect to be partitioned for backend delegation.
Returns:
PartitionResult: includes the tagged graph and the delegation spec to indicate what backend_id and compile_spec is used for each node and the tag created by the backend developers.
Quantizer#
Since the Ethos-U backend is integer-only, all ops intended to run on the NPU needs to be quantized. The Ethos-U quantizer supports Post Training Quantization (PT2E) and Quantization-Aware Training (QAT) quantization.
Currently, the symmetric int8 config defined by executorch.backends.arm.quantizer.arm_quantizer.get_symmetric_quantization_config is
the main config available to use with the Ethos-U quantizer.
class EthosUQuantizer(compile_spec: 'EthosUCompileSpec') -> 'None'
def EthosUQuantizer.set_global(self, quantization_config: 'QuantizationConfig') -> 'TOSAQuantizer':
Set quantization_config for submodules that are not already annotated by name or type filters.
def EthosUQuantizer.set_io(self, quantization_config):
Set quantization_config for input and output nodes.
def EthosUQuantizer.set_module_name(self, module_name: 'str', quantization_config: 'Optional[QuantizationConfig]') -> 'TOSAQuantizer':
Set quantization_config for a submodule with name: module_name, for example:
quantizer.set_module_name(“blocks.sub”), it will quantize all supported operator/operator
patterns in the submodule with this module name with the given quantization_config
def EthosUQuantizer.set_module_type(self, module_type: 'Callable', quantization_config: 'QuantizationConfig') -> 'TOSAQuantizer':
Set quantization_config for a submodule with type: module_type, for example:
quantizer.set_module_name(Sub) or quantizer.set_module_name(nn.Linear), it will quantize all supported operator/operator
patterns in the submodule with this module type with the given quantization_config
def EthosUQuantizer.transform_for_annotation(self, model: 'GraphModule') -> 'GraphModule':
An initial pass for transforming the graph to prepare it for annotation.
Runtime Integration#
An example runtime application is available in examples/arm/executor_runner, and the steps requried for building and deploying it on a FVP it is explained in the previously mentioned Arm Ethos-U Backend Tutorial. The example application is recommended to use for testing basic functionality of your lowered models, as well as a starting point for developing runtime integrations for your own targets. For an in-depth explanation of the architecture of the executor_runner and the steps required for doing such an integration, please refer to Ethos-U porting guide.
Ethos-U memory modes#
The Ethos-U NPU provides two distinct memory interfaces:
One interface for low-latency, high-bandwidth memory.
On all Ethos-U NPUs(Ethos-U55, Ethos-U65, Ethos-U85), the low-latency memory is usually the SRAM of the SoC.
One interface for higher-latency, lower-bandwidth memory, typically external (off-chip) memory.
On a low-power microcontroller, the external memory is usually Flash.
On systems with Arm® Cortex™-A and a rich operating system, the external memory is typically DRAM.
When running an inference, the Ethos-U compiler and Ethos-U driver make use of three logical memory regions:
Ethos-U scratch buffer - a contiguous block of memory used by the NPU to store the intermediate tensors produced and consumed during inference.
Neural Network - a contiguous block of memory holding constant data such as weights, biases, quantization parameters required to run an inference.
Ethos-U fast scratch buffer - a contiguous block of memory, assumed to reside in on-chip memory in order to hide the higher latency/lower bandwidth of external memory. Only applicable for Ethos-U65 and Ethos-U85 on systems with Cortex-A and the external memory is assumed to be DRAM.
The placement of the scratch buffer and the Neural Network determine the memory mode to be used in the EthosUCompileSpec and when building the executor_runner. Three different memory modes are supported:
Memory Mode |
Ethos-U Scratch Buffer Placement |
Neural Network Placement |
When to Use |
Trade-off |
|---|---|---|---|---|
SRAM-Only |
On-chip SRAM |
On-chip SRAM |
When the ML model, the Ethos-U scratch buffer and the wider software stack fit within the SRAM of the SoC |
Limited by SRAM size; often not feasible for larger NNs |
Shared-SRAM |
On-chip SRAM |
External memory (Flash/DRAM) |
Most common mode on Cortex-M and Ethos-U systems; balances good performance and SRAM usage |
Requires enough SRAM to hold the largest intermediate tensor |
Dedicated-SRAM |
External memory |
External memory (Flash/DRAM) |
Most common mode for Cortex-A and Ethos-U systems. For very large models where the peak intermediates cannot fit in SRAM |
Need high-bandwidth external memory to deliver good performance |
Here is an in-depth explanation of the different modes:
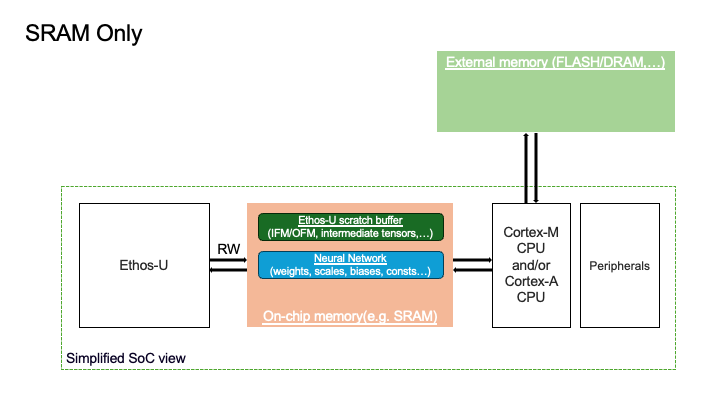
1. Sram-Only Memory Mode#
Ethos-U scratch buffer resides in the SRAM.
Neural Network resides in the SRAM.
Ethos-U fast scratch buffer is not used.
Characteristics:
Provides the best performance since all the memory traffic passes via the low-latency/high-bandwidth memory.
The performance uplift is especially noticeable on memory-bound workloads on the external interface.
Available on Ethos-U55, Ethos-U65 and Ethos-U85.
Limitations:
Embedded SoCs often have limited SRAM and NNs are becoming larger. This memory mode may be unsuitable for a system running a big model relative to the amount of SRAM available on the SoC. Below, you can see a visual representation of the placement of the two logical memory regions for the Sram Only configuration.
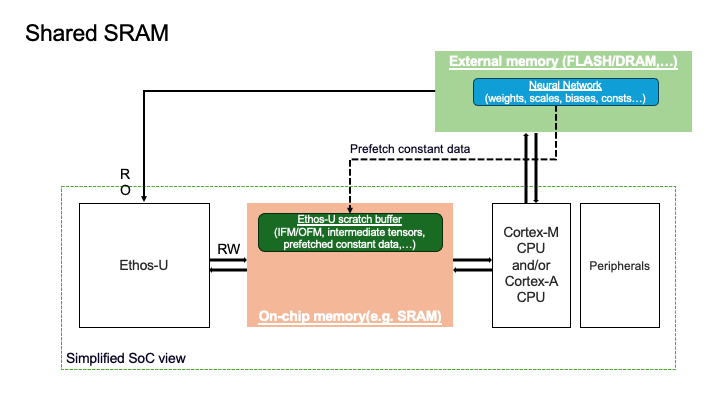
2. Shared-Sram Memory Mode#
Ethos-U scratch buffer resides in the SRAM.
Neural Network resides in the External memory.
Ethos-U fast scratch buffer is not used.
Characteristics:
Intermediate tensors are stored in the SRAM, leveraging its low-latency and high-bandwidth.
The Ethos-U compiler can prefetch weights from the external memory to the SRAM ahead of time so that when the NPU needs the data, it will already be avaialbe in the on-chip memory.
In this mode, the external interface is Read-Only, the on-chip memory interface is Read/Write
Shared-Sram offers great balance between performance and low SRAM usage.
Available on Ethos-U55, Ethos-U65 and Ethos-U85.
Limitations:
You need to have enough space in the SRAM to hold the peak intermediate tensor. Below, you can see a visual representation of the placement of the two logical memory regions for the Shared_Sram configuration.
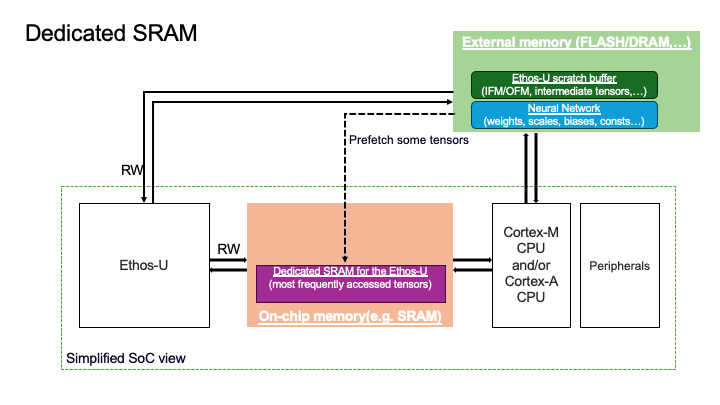
3. Dedicated-Sram Memory Mode#
Ethos-U scratch buffer resides in the External memory.
Neural Network resides in the External memory.
Ethos-U fast scratch buffer resides in the on-chip memory.
Characteristics:
Used when the peak intermediate tensor is too big to fit into the on-chip memory.
Enables silicon acceleration of large models.
The NPU stores the results from the intermediate computations in the external memory.
The dedicated SRAM acts as a software managed cache, improving performance by pre-fetching frequently accessed tensors to the on-chip memory.
Available on Ethos-U65 and Ethos-U85.
Limitations:
The SRAM space must be dedicated exculisely to the Ethos-U(the host processor should not access it).
Not available on Ethos-U55. Below, you can see a visual representation of the placement of the two logical memory regions for the Shared_Sram configuration.
The memory modes are defined within the vela.ini file. When you install ExecuTorch for the Ethos-U backend, you automatically install the compiler containing the vela.ini file so you can directly create a compile specification with these memory modes.
Interpreting the output from the Ethos-U compiler regarding the memory footprint#
As part of the to_edge_transform_and_lower step, you will see a memory footprint information presented as:
Total SRAM used 2467.27 KiB
Total Off-chip Flash used 12.20 KiB
The Total SRAM used indicates the peak SRAM utilization needed by the NPU in order to perform an inference. In the snippet above, the Ethos-U compiler requires 2467.27 KiB of SRAM in order to schedule the inference.
Therefore, from an application standpoint, you need to ensure you have at least 2467.27 KiB of SRAM on the SoC to run this model. The Ethos-U compiler provides a scheduling algorithm allowing to
lower the peak SRAM usage within reasonable limits, you need to add the --optimise Size or --arena-cache-size CLI options for to the compile spec. You can read more about the options of the
Ethos-U compiler in the documentation here. If the peak SRAM usage remains too high in
Shared Sram memory mode, you would need to us the Dedicated Sram mode in order to store the Neural Network and the Ethos-U scratch buffer in the external memory.
The main advantage of the Dedicated_Sram memory mode is that you can run large models and still benefit from the low-latency/high-bandwidth of the SRAM, used as a cache.
It is important to highlight that when you specify a memory mode in the compile spec, in the runtime, the user is expected to place the scratch buffer and NN in the correct memory location.
In other words, when you specify for ex. Shared Sram memory mode, the runtime application logic should place the ethos-U scratch buffer in the on-chip memory and the NN in the external memory for optimal performance.
You can see how this coupling between the memory mode and runtime application is done in the
Ethos-U porting guide
Bundled.io and ETdump#
The arm_executor_runner supports bundled-io and ETdump debugging tools.
To enable bundled-io, set EXECUTORCH_BUILD_DEVTOOLS when building Executorch and DET_BUNDLE_IO when building the executor_runner. Currently using bundled-io requires specifying your
non delegated Aten ops manually by setting EXECUTORCH_SELECT_OPS_LIST. To enable ETdump, set EXECUTORCH_BUILD_ARM_ETDUMP when building Executorch and DEXECUTORCH_ENABLE_EVENT_TRACER
when building the executor_runner.
Memory formats#
Tensors of rank 4 and higher have two differing memory format standards used. Pytorch defaults to contiguous/ channels first/ NCHW memory formats, compared to TOSA which only supports channels last/NHWC memory format. To support this, the backend inserts a transpose in the beginning if the incoming memory format is contiguous, and correspondingly a transpose in the end if the outgoing memory format is contiguous. Note that this means that you may avoid transposing the data unneccessarily if the runtime integration and full network is converted to use channels last. A word of caution must be given here however - changing memory format has been noted to have side effects such as unsupported ops being inserted into the graph, and it is currently not widely tested, so the feature must so far be viewed as experimental.
