


Note
Go to the end to download the full example code.
TensorDictModule¶
In this tutorial you will learn how to use TensorDictModule and
TensorDictSequential to create generic and reusable modules that can accept
TensorDict as input.
For a convenient usage of the TensorDict class with nn.Module,
tensordict provides an interface between the two named TensorDictModule.
The TensorDictModule class is an nn.Module that takes a
TensorDict as input when called.
It is up to the user to define the keys to be read as input and output.
TensorDictModule by examples¶
import torch
import torch.nn as nn
from tensordict import TensorDict
from tensordict.nn import TensorDictModule, TensorDictSequential
Example 1: Simple usage¶
We have a TensorDict with 2 entries "a" and "b" but only the
value associated with "a" has to be read by the network.
tensordict = TensorDict(
{"a": torch.randn(5, 3), "b": torch.zeros(5, 4, 3)},
batch_size=[5],
)
linear = TensorDictModule(nn.Linear(3, 10), in_keys=["a"], out_keys=["a_out"])
linear(tensordict)
assert (tensordict.get("b") == 0).all()
print(tensordict)
TensorDict(
fields={
a: Tensor(shape=torch.Size([5, 3]), device=cpu, dtype=torch.float32, is_shared=False),
a_out: Tensor(shape=torch.Size([5, 10]), device=cpu, dtype=torch.float32, is_shared=False),
b: Tensor(shape=torch.Size([5, 4, 3]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([5]),
device=None,
is_shared=False)
Example 2: Multiple inputs¶
Suppose we have a slightly more complex network that takes 2 entries and
averages them into a single output tensor. To make a TensorDictModule
instance read multiple input values, one must register them in the
in_keys keyword argument of the constructor.
tensordict = TensorDict(
{
"a": torch.randn(5, 3),
"b": torch.randn(5, 4),
},
batch_size=[5],
)
mergelinear = TensorDictModule(
MergeLinear(3, 4, 10), in_keys=["a", "b"], out_keys=["output"]
)
mergelinear(tensordict)
TensorDict(
fields={
a: Tensor(shape=torch.Size([5, 3]), device=cpu, dtype=torch.float32, is_shared=False),
b: Tensor(shape=torch.Size([5, 4]), device=cpu, dtype=torch.float32, is_shared=False),
output: Tensor(shape=torch.Size([5, 10]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([5]),
device=None,
is_shared=False)
Example 3: Multiple outputs¶
Similarly, TensorDictModule not only supports multiple inputs but also
multiple outputs. To make a TensorDictModule instance write to multiple
output values, one must register them in the out_keys keyword argument
of the constructor.
tensordict = TensorDict({"a": torch.randn(5, 3)}, batch_size=[5])
splitlinear = TensorDictModule(
MultiHeadLinear(3, 4, 10),
in_keys=["a"],
out_keys=["output_1", "output_2"],
)
splitlinear(tensordict)
TensorDict(
fields={
a: Tensor(shape=torch.Size([5, 3]), device=cpu, dtype=torch.float32, is_shared=False),
output_1: Tensor(shape=torch.Size([5, 4]), device=cpu, dtype=torch.float32, is_shared=False),
output_2: Tensor(shape=torch.Size([5, 10]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([5]),
device=None,
is_shared=False)
When having multiple input keys and output keys, make sure they match the order in the module.
TensorDictModule can work with TensorDict instances that contain
more tensors than what the in_keys attribute indicates.
Unless a vmap operator is used, the TensorDict is modified in-place.
Ignoring some outputs
Note that it is possible to avoid writing some of the tensors to the
TensorDict output, using "_" in out_keys.
Example 4: Combining multiple TensorDictModule with TensorDictSequential¶
To combine multiple TensorDictModule instances, we can use
TensorDictSequential. We create a list where each TensorDictModule must
be executed sequentially. TensorDictSequential will read and write keys to the
tensordict following the sequence of modules provided.
We can also gather the inputs needed by TensorDictSequential with the
in_keys property, and the outputs keys are found at the out_keys attribute.
tensordict = TensorDict({"a": torch.randn(5, 3)}, batch_size=[5])
splitlinear = TensorDictModule(
MultiHeadLinear(3, 4, 10),
in_keys=["a"],
out_keys=["output_1", "output_2"],
)
mergelinear = TensorDictModule(
MergeLinear(4, 10, 13),
in_keys=["output_1", "output_2"],
out_keys=["output"],
)
split_and_merge_linear = TensorDictSequential(splitlinear, mergelinear)
assert split_and_merge_linear(tensordict)["output"].shape == torch.Size([5, 13])
Do’s and don’t with TensorDictModule¶
Don’t use nn.Sequence, similar to nn.Module, it would break features
such as functorch compatibility. Do use TensorDictSequential instead.
Don’t assign the output tensordict to a new variable, as the output tensordict is just the input modified in-place:
tensordict = module(tensordict) # ok!
tensordict_out = module(tensordict) # don’t!
ProbabilisticTensorDictModule¶
ProbabilisticTensorDictModule is a non-parametric module representing a
probability distribution. Distribution parameters are read from tensordict
input, and the output is written to an output tensordict. The output is
sampled given some rule, specified by the input default_interaction_type
argument and the exploration_mode() global function. If they conflict,
the context manager precedes.
It can be wired together with a TensorDictModule that returns
a tensordict updated with the distribution parameters using
ProbabilisticTensorDictSequential. This is a special case of
TensorDictSequential that terminates in a
ProbabilisticTensorDictModule.
ProbabilisticTensorDictModule is responsible for constructing the
distribution (through the get_dist() method) and/or sampling from this
distribution (through a regular __call__() to the module). The same
get_dist() method is exposed on ``ProbabilisticTensorDictSequential.
One can find the parameters in the output tensordict as well as the log probability if needed.
from tensordict.nn import (
ProbabilisticTensorDictModule,
ProbabilisticTensorDictSequential,
)
from tensordict.nn.distributions import NormalParamExtractor
from torch import distributions as dist
td = TensorDict({"input": torch.randn(3, 4), "hidden": torch.randn(3, 8)}, [3])
net = torch.nn.GRUCell(4, 8)
net = TensorDictModule(net, in_keys=["input", "hidden"], out_keys=["hidden"])
extractor = NormalParamExtractor()
extractor = TensorDictModule(extractor, in_keys=["hidden"], out_keys=["loc", "scale"])
td_module = ProbabilisticTensorDictSequential(
net,
extractor,
ProbabilisticTensorDictModule(
in_keys=["loc", "scale"],
out_keys=["action"],
distribution_class=dist.Normal,
return_log_prob=True,
),
)
print(f"TensorDict before going through module: {td}")
td_module(td)
print(f"TensorDict after going through module now as keys action, loc and scale: {td}")
TensorDict before going through module: TensorDict(
fields={
hidden: Tensor(shape=torch.Size([3, 8]), device=cpu, dtype=torch.float32, is_shared=False),
input: Tensor(shape=torch.Size([3, 4]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([3]),
device=None,
is_shared=False)
TensorDict after going through module now as keys action, loc and scale: TensorDict(
fields={
action: Tensor(shape=torch.Size([3, 4]), device=cpu, dtype=torch.float32, is_shared=False),
hidden: Tensor(shape=torch.Size([3, 8]), device=cpu, dtype=torch.float32, is_shared=False),
input: Tensor(shape=torch.Size([3, 4]), device=cpu, dtype=torch.float32, is_shared=False),
loc: Tensor(shape=torch.Size([3, 4]), device=cpu, dtype=torch.float32, is_shared=False),
sample_log_prob: Tensor(shape=torch.Size([3, 4]), device=cpu, dtype=torch.float32, is_shared=False),
scale: Tensor(shape=torch.Size([3, 4]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([3]),
device=None,
is_shared=False)
Showcase: Implementing a transformer using TensorDictModule¶
To demonstrate the flexibility of TensorDictModule, we are going to
create a transformer that reads TensorDict objects using TensorDictModule.
The following figure shows the classical transformer architecture (Vaswani et al, 2017).
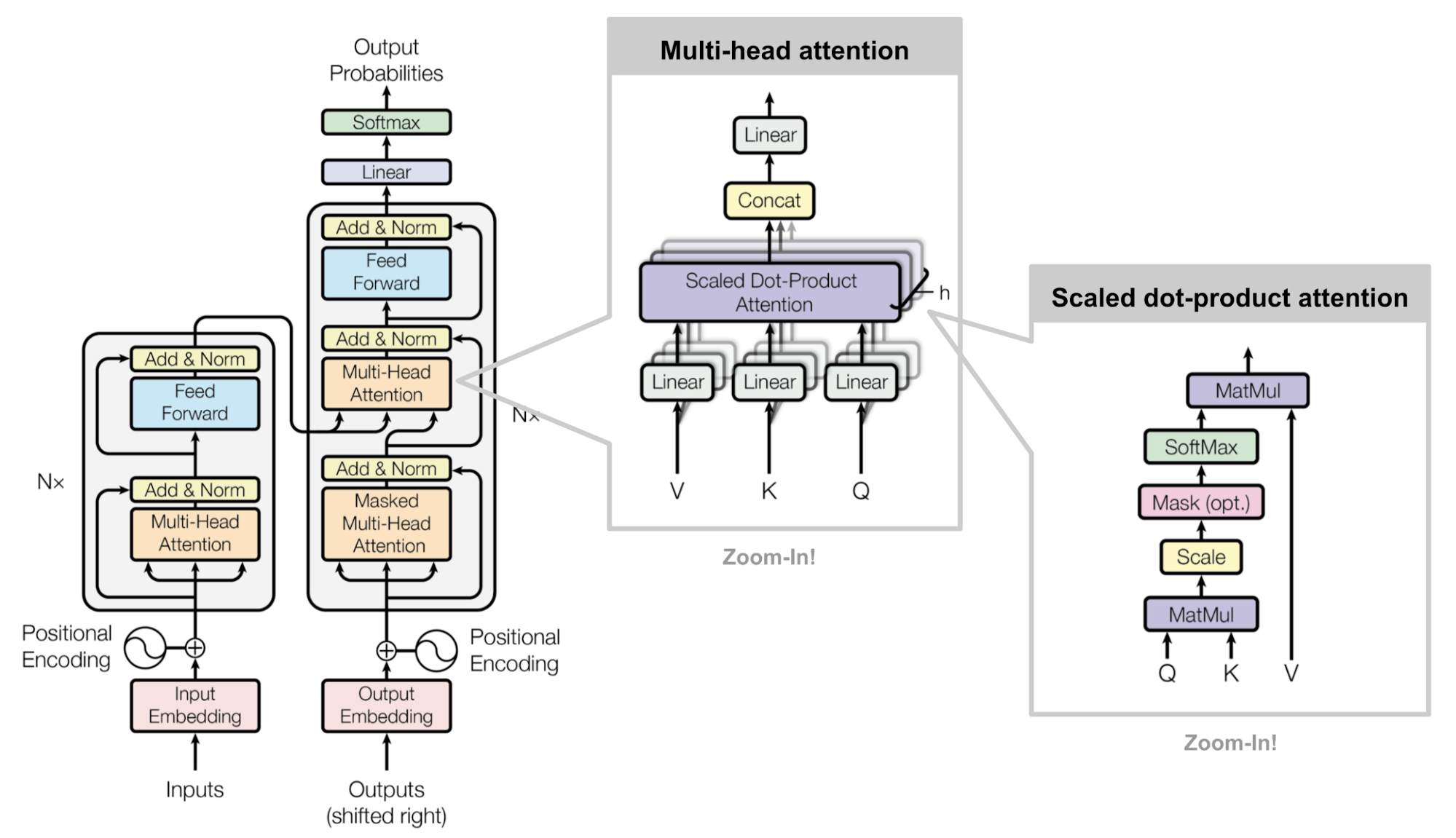
We have let the positional encoders aside for simplicity.
Let’s re-write the classical transformers blocks:
class TokensToQKV(nn.Module):
def __init__(self, to_dim, from_dim, latent_dim):
super().__init__()
self.q = nn.Linear(to_dim, latent_dim)
self.k = nn.Linear(from_dim, latent_dim)
self.v = nn.Linear(from_dim, latent_dim)
def forward(self, X_to, X_from):
Q = self.q(X_to)
K = self.k(X_from)
V = self.v(X_from)
return Q, K, V
class SplitHeads(nn.Module):
def __init__(self, num_heads):
super().__init__()
self.num_heads = num_heads
def forward(self, Q, K, V):
batch_size, to_num, latent_dim = Q.shape
_, from_num, _ = K.shape
d_tensor = latent_dim // self.num_heads
Q = Q.reshape(batch_size, to_num, self.num_heads, d_tensor).transpose(1, 2)
K = K.reshape(batch_size, from_num, self.num_heads, d_tensor).transpose(1, 2)
V = V.reshape(batch_size, from_num, self.num_heads, d_tensor).transpose(1, 2)
return Q, K, V
class Attention(nn.Module):
def __init__(self, latent_dim, to_dim):
super().__init__()
self.softmax = nn.Softmax(dim=-1)
self.out = nn.Linear(latent_dim, to_dim)
def forward(self, Q, K, V):
batch_size, n_heads, to_num, d_in = Q.shape
attn = self.softmax(Q @ K.transpose(2, 3) / d_in)
out = attn @ V
out = self.out(out.transpose(1, 2).reshape(batch_size, to_num, n_heads * d_in))
return out, attn
class SkipLayerNorm(nn.Module):
def __init__(self, to_len, to_dim):
super().__init__()
self.layer_norm = nn.LayerNorm((to_len, to_dim))
def forward(self, x_0, x_1):
return self.layer_norm(x_0 + x_1)
class FFN(nn.Module):
def __init__(self, to_dim, hidden_dim, dropout_rate=0.2):
super().__init__()
self.FFN = nn.Sequential(
nn.Linear(to_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, to_dim),
nn.Dropout(dropout_rate),
)
def forward(self, X):
return self.FFN(X)
class AttentionBlock(nn.Module):
def __init__(self, to_dim, to_len, from_dim, latent_dim, num_heads):
super().__init__()
self.tokens_to_qkv = TokensToQKV(to_dim, from_dim, latent_dim)
self.split_heads = SplitHeads(num_heads)
self.attention = Attention(latent_dim, to_dim)
self.skip = SkipLayerNorm(to_len, to_dim)
def forward(self, X_to, X_from):
Q, K, V = self.tokens_to_qkv(X_to, X_from)
Q, K, V = self.split_heads(Q, K, V)
out, attention = self.attention(Q, K, V)
out = self.skip(X_to, out)
return out
class EncoderTransformerBlock(nn.Module):
def __init__(self, to_dim, to_len, latent_dim, num_heads):
super().__init__()
self.attention_block = AttentionBlock(
to_dim, to_len, to_dim, latent_dim, num_heads
)
self.FFN = FFN(to_dim, 4 * to_dim)
self.skip = SkipLayerNorm(to_len, to_dim)
def forward(self, X_to):
X_to = self.attention_block(X_to, X_to)
X_out = self.FFN(X_to)
return self.skip(X_out, X_to)
class DecoderTransformerBlock(nn.Module):
def __init__(self, to_dim, to_len, from_dim, latent_dim, num_heads):
super().__init__()
self.attention_block = AttentionBlock(
to_dim, to_len, from_dim, latent_dim, num_heads
)
self.encoder_block = EncoderTransformerBlock(
to_dim, to_len, latent_dim, num_heads
)
def forward(self, X_to, X_from):
X_to = self.attention_block(X_to, X_from)
X_to = self.encoder_block(X_to)
return X_to
class TransformerEncoder(nn.Module):
def __init__(self, num_blocks, to_dim, to_len, latent_dim, num_heads):
super().__init__()
self.encoder = nn.ModuleList(
[
EncoderTransformerBlock(to_dim, to_len, latent_dim, num_heads)
for i in range(num_blocks)
]
)
def forward(self, X_to):
for i in range(len(self.encoder)):
X_to = self.encoder[i](X_to)
return X_to
class TransformerDecoder(nn.Module):
def __init__(self, num_blocks, to_dim, to_len, from_dim, latent_dim, num_heads):
super().__init__()
self.decoder = nn.ModuleList(
[
DecoderTransformerBlock(to_dim, to_len, from_dim, latent_dim, num_heads)
for i in range(num_blocks)
]
)
def forward(self, X_to, X_from):
for i in range(len(self.decoder)):
X_to = self.decoder[i](X_to, X_from)
return X_to
class Transformer(nn.Module):
def __init__(
self, num_blocks, to_dim, to_len, from_dim, from_len, latent_dim, num_heads
):
super().__init__()
self.encoder = TransformerEncoder(
num_blocks, to_dim, to_len, latent_dim, num_heads
)
self.decoder = TransformerDecoder(
num_blocks, from_dim, from_len, to_dim, latent_dim, num_heads
)
def forward(self, X_to, X_from):
X_to = self.encoder(X_to)
X_out = self.decoder(X_from, X_to)
return X_out
We first create the AttentionBlockTensorDict, the attention block using
TensorDictModule and TensorDictSequential.
The wiring operation that connects the modules to each other requires us
to indicate which key each of them must read and write. Unlike
nn.Sequence, a TensorDictSequential can read/write more than one
input/output. Moreover, its components inputs need not be identical to the
previous layers outputs, allowing us to code complicated neural architecture.
class AttentionBlockTensorDict(TensorDictSequential):
def __init__(
self,
to_name,
from_name,
to_dim,
to_len,
from_dim,
latent_dim,
num_heads,
):
super().__init__(
TensorDictModule(
TokensToQKV(to_dim, from_dim, latent_dim),
in_keys=[to_name, from_name],
out_keys=["Q", "K", "V"],
),
TensorDictModule(
SplitHeads(num_heads),
in_keys=["Q", "K", "V"],
out_keys=["Q", "K", "V"],
),
TensorDictModule(
Attention(latent_dim, to_dim),
in_keys=["Q", "K", "V"],
out_keys=["X_out", "Attn"],
),
TensorDictModule(
SkipLayerNorm(to_len, to_dim),
in_keys=[to_name, "X_out"],
out_keys=[to_name],
),
)
We build the encoder and decoder blocks that will be part of the transformer
thanks to TensorDictModule.
class TransformerBlockEncoderTensorDict(TensorDictSequential):
def __init__(
self,
to_name,
from_name,
to_dim,
to_len,
from_dim,
latent_dim,
num_heads,
):
super().__init__(
AttentionBlockTensorDict(
to_name,
from_name,
to_dim,
to_len,
from_dim,
latent_dim,
num_heads,
),
TensorDictModule(
FFN(to_dim, 4 * to_dim),
in_keys=[to_name],
out_keys=["X_out"],
),
TensorDictModule(
SkipLayerNorm(to_len, to_dim),
in_keys=[to_name, "X_out"],
out_keys=[to_name],
),
)
class TransformerBlockDecoderTensorDict(TensorDictSequential):
def __init__(
self,
to_name,
from_name,
to_dim,
to_len,
from_dim,
latent_dim,
num_heads,
):
super().__init__(
AttentionBlockTensorDict(
to_name,
to_name,
to_dim,
to_len,
to_dim,
latent_dim,
num_heads,
),
TransformerBlockEncoderTensorDict(
to_name,
from_name,
to_dim,
to_len,
from_dim,
latent_dim,
num_heads,
),
)
We create the transformer encoder and decoder.
For an encoder, we just need to take the same tokens for both queries, keys and values.
For a decoder, we now can extract info from X_from into X_to.
X_from will map to queries whereas X_from will map to keys and values.
class TransformerEncoderTensorDict(TensorDictSequential):
def __init__(
self,
num_blocks,
to_name,
from_name,
to_dim,
to_len,
from_dim,
latent_dim,
num_heads,
):
super().__init__(
*[
TransformerBlockEncoderTensorDict(
to_name,
from_name,
to_dim,
to_len,
from_dim,
latent_dim,
num_heads,
)
for _ in range(num_blocks)
]
)
class TransformerDecoderTensorDict(TensorDictSequential):
def __init__(
self,
num_blocks,
to_name,
from_name,
to_dim,
to_len,
from_dim,
latent_dim,
num_heads,
):
super().__init__(
*[
TransformerBlockDecoderTensorDict(
to_name,
from_name,
to_dim,
to_len,
from_dim,
latent_dim,
num_heads,
)
for _ in range(num_blocks)
]
)
class TransformerTensorDict(TensorDictSequential):
def __init__(
self,
num_blocks,
to_name,
from_name,
to_dim,
to_len,
from_dim,
from_len,
latent_dim,
num_heads,
):
super().__init__(
TransformerEncoderTensorDict(
num_blocks,
to_name,
to_name,
to_dim,
to_len,
to_dim,
latent_dim,
num_heads,
),
TransformerDecoderTensorDict(
num_blocks,
from_name,
to_name,
from_dim,
from_len,
to_dim,
latent_dim,
num_heads,
),
)
We now test our new TransformerTensorDict.
to_dim = 5
from_dim = 6
latent_dim = 10
to_len = 3
from_len = 10
batch_size = 8
num_heads = 2
num_blocks = 6
tokens = TensorDict(
{
"X_encode": torch.randn(batch_size, to_len, to_dim),
"X_decode": torch.randn(batch_size, from_len, from_dim),
},
batch_size=[batch_size],
)
transformer = TransformerTensorDict(
num_blocks,
"X_encode",
"X_decode",
to_dim,
to_len,
from_dim,
from_len,
latent_dim,
num_heads,
)
transformer(tokens)
tokens
TensorDict(
fields={
Attn: Tensor(shape=torch.Size([8, 2, 10, 3]), device=cpu, dtype=torch.float32, is_shared=False),
K: Tensor(shape=torch.Size([8, 2, 3, 5]), device=cpu, dtype=torch.float32, is_shared=False),
Q: Tensor(shape=torch.Size([8, 2, 10, 5]), device=cpu, dtype=torch.float32, is_shared=False),
V: Tensor(shape=torch.Size([8, 2, 3, 5]), device=cpu, dtype=torch.float32, is_shared=False),
X_decode: Tensor(shape=torch.Size([8, 10, 6]), device=cpu, dtype=torch.float32, is_shared=False),
X_encode: Tensor(shape=torch.Size([8, 3, 5]), device=cpu, dtype=torch.float32, is_shared=False),
X_out: Tensor(shape=torch.Size([8, 10, 6]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([8]),
device=None,
is_shared=False)
We’ve achieved to create a transformer with TensorDictModule. This
shows that TensorDictModule is a flexible module that can implement
complex operarations.
Benchmarking¶
to_dim = 5
from_dim = 6
latent_dim = 10
to_len = 3
from_len = 10
batch_size = 8
num_heads = 2
num_blocks = 6
td_tokens = TensorDict(
{
"X_encode": torch.randn(batch_size, to_len, to_dim),
"X_decode": torch.randn(batch_size, from_len, from_dim),
},
batch_size=[batch_size],
)
tdtransformer = TransformerTensorDict(
num_blocks,
"X_encode",
"X_decode",
to_dim,
to_len,
from_dim,
from_len,
latent_dim,
num_heads,
)
transformer = Transformer(
num_blocks, to_dim, to_len, from_dim, from_len, latent_dim, num_heads
)
Inference Time
import time
Execution time: 0.009625911712646484 seconds
Execution time: 0.006480216979980469 seconds
We can see on this minimal example that the overhead introduced by
TensorDictModule is marginal.
Have fun with TensorDictModule!
Total running time of the script: (0 minutes 10.088 seconds)
