


Transforms#
In most cases, the raw output of an environment must be treated before being passed to another object (such as a policy or a value operator). To do this, TorchRL provides a set of transforms that aim at reproducing the transform logic of torch.distributions.Transform and torchvision.transforms. Our environment tutorial provides more information on how to design a custom transform.
Transformed environments are build using the TransformedEnv primitive.
Composed transforms are built using the Compose class:
>>> base_env = GymEnv("Pendulum-v1", from_pixels=True, device="cuda:0")
>>> transform = Compose(ToTensorImage(in_keys=["pixels"]), Resize(64, 64, in_keys=["pixels"]))
>>> env = TransformedEnv(base_env, transform)
Transforms are usually subclasses of Transform, although any
Callable[[TensorDictBase], TensorDictBase].
By default, the transformed environment will inherit the device of the
base_env that is passed to it. The transforms will then be executed on that device.
It is now apparent that this can bring a significant speedup depending on the kind of
operations that is to be computed.
A great advantage of environment wrappers is that one can consult the environment up to that wrapper.
The same can be achieved with TorchRL transformed environments: the parent attribute will
return a new TransformedEnv with all the transforms up to the transform of interest.
Reusing the example above:
>>> resize_parent = env.transform[-1].parent # returns the same as TransformedEnv(base_env, transform[:-1])
Transformed environment can be used with vectorized environments.
Since each transform uses a "in_keys"/"out_keys" set of keyword argument, it is
also easy to root the transform graph to each component of the observation data (e.g.
pixels or states etc).
Forward and inverse transforms#
Transforms also have an inv() method that is called before the action is applied in reverse
order over the composed transform chain. This allows applying transforms to data in the environment before the action is
taken in the environment. The keys to be included in this inverse transform are passed through the “in_keys_inv”
keyword argument, and the out-keys default to these values in most cases:
>>> env.append_transform(DoubleToFloat(in_keys_inv=["action"])) # will map the action from float32 to float64 before calling the base_env.step
The following paragraphs detail how one can think about what is to be considered in_ or out_ features.
Understanding Transform Keys#
In transforms, in_keys and out_keys define the interaction between the base environment and the outside world (e.g., your policy):
in_keys refers to the base environment’s perspective (inner = base_env of the
TransformedEnv).out_keys refers to the outside world (outer = policy, agent, etc.).
For example, with in_keys=[“obs”] and out_keys=[“obs_standardized”], the policy will “see” a standardized observation, while the base environment outputs a regular observation.
Similarly, for inverse keys:
in_keys_inv refers to entries as seen by the base environment.
out_keys_inv refers to entries as seen or produced by the policy.
The following figure illustrates this concept for the RenameTransform class: the input
TensorDict of the step function must include the out_keys_inv as they are part of the outside world. The
transform changes these names to match the names of the inner, base environment using the in_keys_inv.
The inverse process is executed with the output tensordict, where the in_keys are mapped to the corresponding
out_keys.
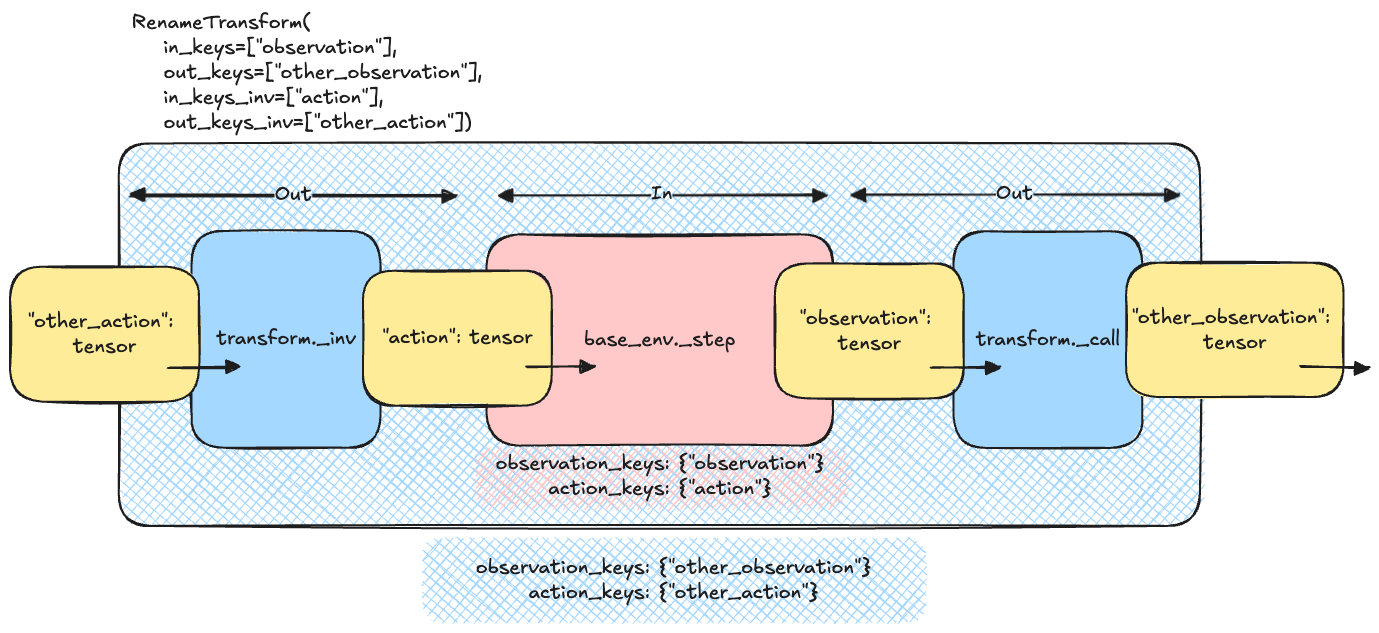
Rename transform logic#
Note
During a call to inv, the transforms are executed in reversed order (compared to the forward / step mode).
Transforming Tensors and Specs#
When transforming actual tensors (coming from the policy), the process is schematically represented as:
>>> for t in reversed(self.transform):
... td = t.inv(td)
This starts with the outermost transform to the innermost transform, ensuring the action value exposed to the policy is properly transformed.
For transforming the action spec, the process should go from innermost to outermost (similar to observation specs):
>>> def transform_action_spec(self, action_spec):
... for t in self.transform:
... action_spec = t.transform_action_spec(action_spec)
... return action_spec
A pseudocode for a single transform_action_spec could be:
>>> def transform_action_spec(self, action_spec):
... return spec_from_random_values(self._apply_transform(action_spec.rand()))
This approach ensures that the “outside” spec is inferred from the “inside” spec. Note that we did not call _inv_apply_transform but _apply_transform on purpose!
Exposing Specs to the Outside World#
TransformedEnv will expose the specs corresponding to the out_keys_inv for actions and states.
For example, with ActionDiscretizer, the environment’s action (e.g., “action”) is a float-valued
tensor that should not be generated when using rand_action() with the transformed
environment. Instead, “action_discrete” should be generated, and its continuous counterpart obtained from the
transform. Therefore, the user should see the “action_discrete” entry being exposed, but not “action”.
Designing your own Transform#
To create a basic, custom transform, you need to subclass the Transform class and implement the
_apply_transform() method. Here’s an example of a simple transform that adds 1 to the observation
tensor:
>>> class AddOneToObs(Transform):
... """A transform that adds 1 to the observation tensor."""
...
... def __init__(self):
... super().__init__(in_keys=["observation"], out_keys=["observation"])
...
... def _apply_transform(self, obs: torch.Tensor) -> torch.Tensor:
... return obs + 1
Tips for subclassing Transform#
There are various ways of subclassing a transform. The things to take into considerations are:
Is the transform identical for each tensor / item being transformed? Use
_apply_transform()and_inv_apply_transform().The transform needs access to the input data to env.step as well as output? Rewrite
_step(). Otherwise, rewrite_call()(or_inv_call()).Is the transform to be used within a replay buffer? Overwrite
forward(),inv(),_apply_transform()or_inv_apply_transform().Within a transform, you can access (and make calls to) the parent environment using
parent(the base env + all transforms till this one) orcontainer()(The object that encapsulates the transform).Don’t forget to edits the specs if needed: top level:
transform_output_spec(),transform_input_spec(). Leaf level:transform_observation_spec(),transform_action_spec(),transform_state_spec(),transform_reward_spec()andtransform_reward_spec().
For practical examples, see the methods listed above.
You can use a transform in an environment by passing it to the TransformedEnv constructor:
>>> env = TransformedEnv(GymEnv("Pendulum-v1"), AddOneToObs())
You can compose multiple transforms together using the Compose class:
>>> transform = Compose(AddOneToObs(), RewardSum())
>>> env = TransformedEnv(GymEnv("Pendulum-v1"), transform)
Inverse Transforms#
Some transforms have an inverse transform that can be used to undo the transformation. For example, the AddOneToAction transform has an inverse transform that subtracts 1 from the action tensor:
>>> class AddOneToAction(Transform):
... """A transform that adds 1 to the action tensor."""
... def __init__(self):
... super().__init__(in_keys=[], out_keys=[], in_keys_inv=["action"], out_keys_inv=["action"])
... def _inv_apply_transform(self, action: torch.Tensor) -> torch.Tensor:
... return action + 1
Using a Transform with a Replay Buffer#
You can use a transform with a replay buffer by passing it to the ReplayBuffer constructor:
Cloning transforms#
Because transforms appended to an environment are “registered” to this environment
through the transform.parent property, when manipulating transforms we should keep
in mind that the parent may come and go following what is being done with the transform.
Here are some examples: if we get a single transform from a Compose object,
this transform will keep its parent:
>>> third_transform = env.transform[2]
>>> assert third_transform.parent is not None
This means that using this transform for another environment is prohibited, as
the other environment would replace the parent and this may lead to unexpected
behaviours. Fortunately, the Transform class comes with a clone()
method that will erase the parent while keeping the identity of all the
registered buffers:
>>> TransformedEnv(base_env, third_transform) # raises an Exception as third_transform already has a parent
>>> TransformedEnv(base_env, third_transform.clone()) # works
On a single process or if the buffers are placed in shared memory, this will
result in all the clone transforms to keep the same behavior even if the
buffers are changed in place (which is what will happen with the CatFrames
transform, for instance). In distributed settings, this may not hold and one
should be careful about the expected behavior of the cloned transforms in this
context.
Finally, notice that indexing multiple transforms from a Compose transform
may also result in loss of parenthood for these transforms: the reason is that
indexing a Compose transform results in another Compose transform
that does not have a parent environment. Hence, we have to clone the sub-transforms
to be able to create this other composition:
>>> env = TransformedEnv(base_env, Compose(transform1, transform2, transform3))
>>> last_two = env.transform[-2:]
>>> assert isinstance(last_two, Compose)
>>> assert last_two.parent is None
>>> assert last_two[0] is not transform2
>>> assert isinstance(last_two[0], type(transform2)) # and the buffers will match
>>> assert last_two[1] is not transform3
>>> assert isinstance(last_two[1], type(transform3)) # and the buffers will match
Available Transforms#
|
Base class for environment transforms, which modify or create new data in a tensordict. |
|
A transformed environment. |
|
Build fixed-length action chunks from a trajectory window. |
|
A transform to discretize a continuous action space. |
|
An adaptive action masker. |
|
Affine-scale a continuous action using the bounds of the action spec. |
|
Encode and decode actions with an |
|
A subclass for auto-resetting envs. |
|
A transform for auto-resetting environments. |
|
A transform to modify the batch-size of an environment. |
|
Maps the reward to a binary value (0 or 1) if the reward is null or non-null, respectively. |
|
Transform to partially burn-in data sequences. |
|
Concatenates successive observation frames into a single tensor. |
|
Concatenates several keys in a single tensor. |
|
Crops the center of an image. |
|
A transform to clip input (state, action) or output (observation, reward) values. |
|
Composes a chain of transforms. |
|
A transform that conditionally switches between policies based on a specified condition. |
|
A transform that skips steps in the env if certain conditions are met. |
|
Crops the input image at the specified location and output size. |
|
Casts one dtype to another for selected keys. |
|
Decodes |
|
Moves data from one device to another. |
|
Projects discrete actions from a high dimensional space to a low dimensional space. |
|
Casts one dtype to another for selected keys. |
|
Registers the end-of-life signal from a Gym env with a lives method. |
|
Excludes keys from the data. |
|
Expands one entry to the right to match a reference entry shape. |
This transform will check that all the items of the tensordict are finite, and raise an exception if they are not. |
|
|
Flatten adjacent dimensions of an action. |
|
Flatten adjacent dimensions of a tensor. |
|
A frame-skip transform. |
|
Turns a pixel observation to grayscale. |
|
Adds a hash value to a tensordict. |
|
|
|
Reset tracker. |
|
Transforms a multi-objective reward signal to a single-objective one via a weighted sum. |
|
|
|
Generic primitive ids understood by |
|
Expand a high-level macro action into a low-level action sequence. |
|
|
|
|
|
Readable modes for |
|
|
|
Expand desired satellite attitudes into CMG gimbal-rate sequences. |
|
Integer ids for URScript-style robot primitives. |
|
Bridges Gaussian belief-space policies with standard environments. |
|
A transform that wraps a module. |
|
A transform to execute multiple actions in the parent environment. |
|
Stores |
|
Re-hydrate |
|
Runs a series of random actions when an environment is reset. |
|
Observation affine transformation layer. |
|
Abstract class for transformations of the observations. |
|
Permutation transform. |
Calls pin_memory on the tensordict to facilitate writing on CUDA devices. |
|
|
R3M Transform class. |
|
A trajectory sub-sampler for ReplayBuffer and modules. |
|
Randomly truncate episodes to decorrelate synchronized batched envs. |
|
Removes empty specs and content from an environment. |
|
A transform to rename entries in the output tensordict (or input tensordict via the inverse keys). |
|
Resizes a pixel observation. |
|
Random Network Distillation transform that computes an intrinsic reward. |
|
Calculates the reward to go based on the episode reward and a discount factor. |
|
Clips the reward between clamp_min and clamp_max. |
|
Affine transform of the reward. |
|
Tracks episode cumulative rewards. |
|
Tracks running mean and variance using Welford's parallel algorithm. |
|
Select keys from the input tensordict. |
|
A transform to compute the signs of TensorDict values. |
|
Removes a dimension of size one at the specified position. |
|
Stacks tensors and tensordicts. |
|
Counts the steps from a reset and optionally sets the truncated state to |
|
Sparse 0/1 success reward for reinforcement fine-tuning. |
|
Sets a target return for the agent to achieve in the environment. |
|
A primer for TensorDict initialization at reset time. |
|
Terminate a rollout when a user-supplied predicate becomes true. |
|
Take the maximum value in each position over the last T observations. |
|
A transform that measures the time intervals between inv and call operations in an environment. |
|
Applies a tokenization operation on the specified inputs. |
|
Transforms a numpy-like image (W x H x C) to a pytorch image (C x W x H). |
|
Global trajectory counter transform. |
|
URScript-style preset of |
|
Applies a unary operation on the specified inputs. |
|
Inserts a dimension of size one at the specified position. |
|
VC1 Transform class. |
|
A VIP transform to compute rewards based on embedded similarity. |
|
VIP Transform class. |
|
A transform for GymWrapper subclasses that handles the auto-reset in a consistent way. |
|
Moving average normalization layer for torchrl environments. |
|
A class for normalizing vectorized observations and rewards in reinforcement learning environments. |
|
A gSDE noise initializer. |
Functional transforms#
Some transforms expose a pure, stateless functional core (the PyTorch
torch.nn.functional / torch.nn.Module split) that can be reused directly
on plain tensors, outside the transform machinery. The stateful transform
delegates to the functional so that the two stay equivalent.
|
Stacks a sliding window of |
Environments with masked actions#
In some environments with discrete actions, the actions available to the agent might change throughout execution.
In such cases the environments will output an action mask (under the "action_mask" key by default).
This mask needs to be used to filter out unavailable actions for that step.
If you are using a custom policy you can pass this mask to your probability distribution like so:
>>> from tensordict.nn import TensorDictModule, ProbabilisticTensorDictModule, TensorDictSequential
>>> import torch.nn as nn
>>> from torchrl.modules import MaskedCategorical
>>> module = TensorDictModule(
>>> nn.Linear(in_feats, out_feats),
>>> in_keys=["observation"],
>>> out_keys=["logits"],
>>> )
>>> dist = ProbabilisticTensorDictModule(
>>> in_keys={"logits": "logits", "mask": "action_mask"},
>>> out_keys=["action"],
>>> distribution_class=MaskedCategorical,
>>> )
>>> actor = TensorDictSequential(module, dist)
If you want to use a default policy, you will need to wrap your environment in the ActionMask
transform. This transform can take care of updating the action mask in the action spec in order for the default policy
to always know what the latest available actions are. You can do this like so:
>>> from tensordict.nn import TensorDictModule, ProbabilisticTensorDictModule, TensorDictSequential
>>> import torch.nn as nn
>>> from torchrl.envs.transforms import TransformedEnv, ActionMask
>>> env = TransformedEnv(
>>> your_base_env
>>> ActionMask(action_key="action", mask_key="action_mask"),
>>> )
Note
In case you are using a parallel environment it is important to add the transform to the parallel environment itself and not to its sub-environments.