Printing and Inspecting Tensors Inside torch.compile
TL;DR – A complete toolkit for inspecting tensors inside
torch.compile— print forward activations, inspect backward gradients, all without graph breaks.
Background / Motivation
Debugging numerical issues inside torch.compile has historically been painful. Any attempt to insert print() or logging calls would trigger graph breaks, defeating the purpose of compilation. Users needed a way to inspect tensor values (shapes, norms, gradients) in both the forward and backward pass without sacrificing compiler guarantees.
In a previous post, we introduced torch._higher_order_ops.print as a graph-break-free printing primitive. Since then, we’ve expanded it into a full toolkit covering forward activations, backward gradients, custom logging, and whole-model instrumentation.
Design / Approach
Decision Tree: Which Tool Should I Use?
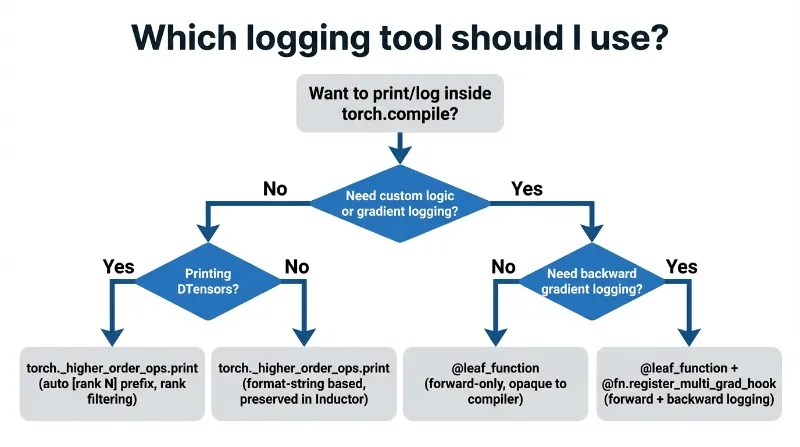
1. torch._higher_order_ops.print — Forward-Pass Printing
The print HOP now supports DTensor and rank filtering, making it usable in distributed settings:
dt = DTensor.from_local(local_shard, device_mesh, [Shard(0)])
@torch.compile(backend="aot_eager", fullgraph=True)
def fn(dt):
y = dt + dt
torch._higher_order_ops.print("activations: {}", y)
return y
fn(dt)
# [rank 0] activations: tensor([0., 1., 2., 3.])
# [rank 1] activations: tensor([4., 5., 6., 7.])
2. @leaf_function — Custom Logging Without Graph Breaks
@leaf_function makes any Python function opaque to the compiler — log to files, compute norms, hash tensors. Pair with register_multi_grad_hook for backward gradients:
@leaf_function
def log_tensor(x, tag=""):
print(f"[{tag}][fwd] shape={x.shape}, norm={x.norm():.4f}")
return None
@log_tensor.register_multi_grad_hook
def log_tensor_hook(x_grad):
print(f"[bwd] grad_norm={x_grad.norm():.4f}")
3. debug_grad_log — One-Liner Gradient Inspection
Drop-in gradient norm logging with zero boilerplate:
from torch.utils.debug_log import debug_grad_log
@torch.compile(backend="aot_eager", fullgraph=True)
def fn(x, y):
a, b = x * 2, y * 3
debug_grad_log(a, b)
return (a + b).sum()
# Output: [rank 0][bwd] t0_grad_norm=2.0000 t1_grad_norm=3.0000
4. install_debug_prints — Instrument Every Module
Auto-instrument an entire nn.Module to see activations and gradients for every layer:
@torch.compile(backend="aot_eager", fullgraph=True)
def fn(x, y):
(a + b).sum()
x = torch.randn(4, requires_grad=True)
y = torch.randn(4, requires_grad=True)
fn(x, y).backward()
# [rank 0][bwd] t0_grad_norm=2.0000 t1_grad_norm=2.0000
Full recipe available in the guide.
Results / Benchmarks
| Need | Tool |
|---|---|
| Print tensors in forward pass | torch._higher_order_ops.print |
| Quick backward gradient norms | debug_grad_log |
| Custom logging (files, norms, hashes) | @leaf_function + register_multi_grad_hook |
| Instrument all layers in a model | install_debug_prints (recipe in guide) |
All tools: ✅ Work with torch.compile · ✅ No graph breaks · ✅ Support DTensor
Open Questions / Future Work
- Agent-assisted debugging: Add printing/logging instructions to your
claude.mdso AI coding agents can automatically insert the right inspection calls insidetorch.compile. - Community feedback wanted:
- What’s your debugging workflow when you hit numerical issues in compiled models?
- Have you tried the print HOP? What worked, what was missing?
- What would you want next?
References
- A quick guide for printing and logging in PT2 programs — Full guide with recipes
- Previous: Introduction of
torch._higher_order_ops.print