Nested Graph Breaks 2025 Update
Summary
The nested graph break problem in torch.compile refers to the Dynamo limitation of only being able to resume from a graph break in the top-level frame. As a result, a graph break in a function O(N) levels deep results in O(N) duplicate graph breaks and O(N^2) traced frames. By enabling Dynamo to resume at an arbitrary frame depth, we can prevent duplicate graph breaks and reduce tracing to O(N) frames.
Preliminary local benchmarking shows that nested graph break enablement will result in reduced graph breaks (18 → 9 and 9 → 2 for 2 OSS benchmark models), better performance (1.38x → 1.42x and 2.47x → 2.53x), and improved debugability. On a pathological microbenchmark, we were able to reduce compile time by almost 15x (504s → 34s).
We have made substantial progress in 2025 in implementing nested graph break handling despite shifting priorities. Today, you can enable nested graph breaks with the config torch._dynamo.config.nested_graph_breaks = True, but there are still some kinks that need to be worked out, so we are not suggesting widespread adoption yet.
In 2026, we are aiming to fix all of the remaining nested graph break issues so that torch._dynamo.config.nested_graph_breaks can be set to True by default.
Motivation
A nested graph break refers to any graph break that happens in a nested function call.
def h(x):
x = x + 3
torch._dynamo.graph_break() # nested graph break
x = x + 4
return x
def g(x):
x = x + 2
x = h(x)
x = x + 5
return x
@torch.compile
def f(x):
x = x + 1
x = g(x)
x = x + 6
return x
Before, Dynamo would trace the graph break 3 times and trace each of the 6 additions into individual graphs:
def compiled_fn_1(x):
return x + 1
def compiled_fn_2(x):
return x + 2
def compiled_fn_3(x):
return x + 3
def compiled_fn_4(x):
return x + 4
def compiled_fn_5(x):
return x + 5
def compiled_fn_6(x):
return x + 6
Ideally, Dynamo should only trace the graph break once and trace out 2 graphs with 3 additions each:
def compiled_fn_1(x):
x = x + 1
x = x + 2
x = x + 3
return x
def compiled_fn_2(x):
x = x + 4
x = x + 5
x = x + 6
return x
Dynamo does this because, before, it could only support resuming at the top-level function. In the example above, where f calls g calls h with a graph break in h, then Dynamo’s tracing behavior would be:
- Trace
f, theng, thenh- hit the graph break - In
f’s compiled function, callgas the unsupported function call - Trace
g, thenh- hit the graph break again - In
g’s compiled function, callhas the unsupported function call - Trace
h- hit the graph break again - Resume
hafter the graph break - Resume
g, after the call toh - Resume
f, after the call tog
Thus, a graph break in a function O(N) levels deep results in O(N) duplicate graph breaks and O(N^2) traced frames. This is bad for several reasons:
- Increased tracing time due to tracing the same graph break O(N) times and tracing O(N^2) frames
- Worse optimization opportunities (performance), since we cannot capture ops in different functions in the same FX graph
- Confusing programming model + bad debuggability - duplicate graph breaks show up in tlparse and it is not obvious to users that Dynamo handles nested graph breaks in this manner
See https://docs.pytorch.org/docs/stable/compile/programming_model.nested_graph_breaks.html for more details on nested graph break semantics, plus a worked-through example.
Solution
The solution to the nested graph break problem is to enable Dynamo to resume at an arbitrarily deep frame. This requires substantial changes to how we generate compiled/resume function bytecode. Before handling nested graph breaks, the code for the compiled and resume functions had the following format (omitting many technical details):
def compiled_f(<original f arguments>):
graph_args = <compute graph args from args>
graph_out = compiled_graph(graph_args)
<codegen stack>
<codegen and store locals>
<codegen side effects>
<call unsupported instruction>
return resume_f(*(stack + locals))
def resume_f(*(stack + locals))
<store locals>
<load stack>
<jump to resume instruction>
<original f code>
In order to resume at an arbitrarily deep frame, Dynamo must run the deepest frame’s unsupported instruction, then create and call a resume function for each intermediate frame in order to preserve the call structure. Our updated compiled and resume functions have the following format:
def compiled_function(<original root-frame arguments>):
graph_args = <compute graph args from args>
graph_out = compiled_graph(graph_args)
values = []
for frame in frames: # from leaf frame to root frame
values.append([codegen stack and locals])
<codegen side effects>
<load values[0] stack>
<call unsupported instruction>
<update values[0] stack>
resumes = []
for frame in frames: # from leaf frame to root frame
resumes.append(<resume function for frame>)
return resumes[-1](*[resumes[:-1], values[:-1], *values[-1]])
def resume_function(resumes, values, *(stack + locals)):
<store locals>
<load stack>
if resumes:
result = resumes[-1](*[resumes[:-1], values[:-1], *values[-1]])
<load result to stack>
<jump to resume instruction>
<original code>
Implementation Challenges
output_graph.py / symbolic_convert.py refactors and invariants
output_graph.py is where the FX graph is generated and is also responsible for codegen’ing the parts of the compiled function regardless of graph break/tracing completion. symbolic_convert.py is the entrypoint of Dynamo’s bytecode handler and is also responsible for catching graph breaks and codegen’ing the remainder of the compiled function.
The graph break handling and codegen logic in output_graph.py and symbolic_convert.py had significant documentation gaps, leading to increased implementation difficulty.
Codegen invariants
It turns out that the order of actions in the compiled function matters a lot. Here’s our nested compiled function again, for reference:
def compiled_function(<original root-frame arguments>):
graph_args = <compute graph args from args>
graph_out = compiled_graph(graph_args)
values = []
<codegen stack + locals values for all frames>
<codegen side effects>
<load frame N (values[0]) stack>
<call unsupported instruction>
<update frame N stack in values[0]>
resumes = []
<codegen resume functions>
return resumes[-1](*[resumes[:-1], values[:-1], *values[-1]])
We discovered the following codegen invariants:
- Sourceful
VariableTrackers should not be codegen’d after applying side effects. This is because side effects can change the validity of sources (e.g. if the source points to the top of a list and we pop that list). PR- Concretely, we must codegen cells between
<codegen stack + locals>and<codegen side effects>. We cannot codegen cells in<codegen resume functions>even though the cells are not used until resume function construction.
- Concretely, we must codegen cells between
- We cannot guarantee that
VariableTrackers accurately represent their wrapped values anymore after running the unsupported function since the unsupported function could arbitrarily mutate the underlying objects. There are still a few guarantees that we can make though - for example, we can still guarantee that aVariableTracker’s placement in any frame’s stack is still representative (after we model the instruction’s push/pop stack effect).- Concretely, we cannot
reconstruct(...)aVariableTrackerafter<call unsupported instruction>, but we can still move things around invalues.
- Concretely, we cannot
We discovered these invariants when we encountered bugs when attempting to change the order of some of the codegen out of implementation convenience.
Codegen’d values storage
Because the codegen previously assumed resuming at the top-level frame, we were able to codegen the local values for the frame and store them directly into the frame. Because we now need to codegen the locals and stack for every nested frame, we need to find a new place to store them. We designed the following stack storage conventions for the compiled frame:
"frame 1" refers to the root frame, "frame N" refers to the leaf frame.
compiled frame stack BEFORE the unsupported instruction:
# bottom of stack
[frame N cells, .., frame 1 cells],
[
frame N locals,
frame N-1 stack + locals,
...,
frame 1 stack + locals,
], # i.e. "values" from the above code snippets
frame N stack
# top of stack
The unsupported instruction consumes some items from the top of the stack
(frame N stack values) and pushes back the result.
compiled frame stack AFTER the unsupported instruction (and moving the frame N stack):
# bottom of stack
[frame N cells, ..., frame 1 cells],
[
frame N stack + locals,
frame N-1 stack + locals,
...,
frame 1 stack + locals,
] # i.e. "values"
# top of stack
compiled frame stack BEFORE calling the nested resume function:
# bottom of stack
NULL,
resume frame 1,
[
[resume frame N, ..., resume frame 2],
[
frame N stack + locals,
...
frame 2 stack + locals,
], # "values[:-1]"
frame 1 stack + locals # values[-1]
],
# top of stack
# call: resume_frame_1(*[resumes N to 2, stack/locals N to 2, *(frame 1 stack/locals)])
We had to make substantial changes to the codegen in symbolic_convert.py and output_graph.py to create and manipulate the lists of cells/stack values/locals.
Documenting graph break handling
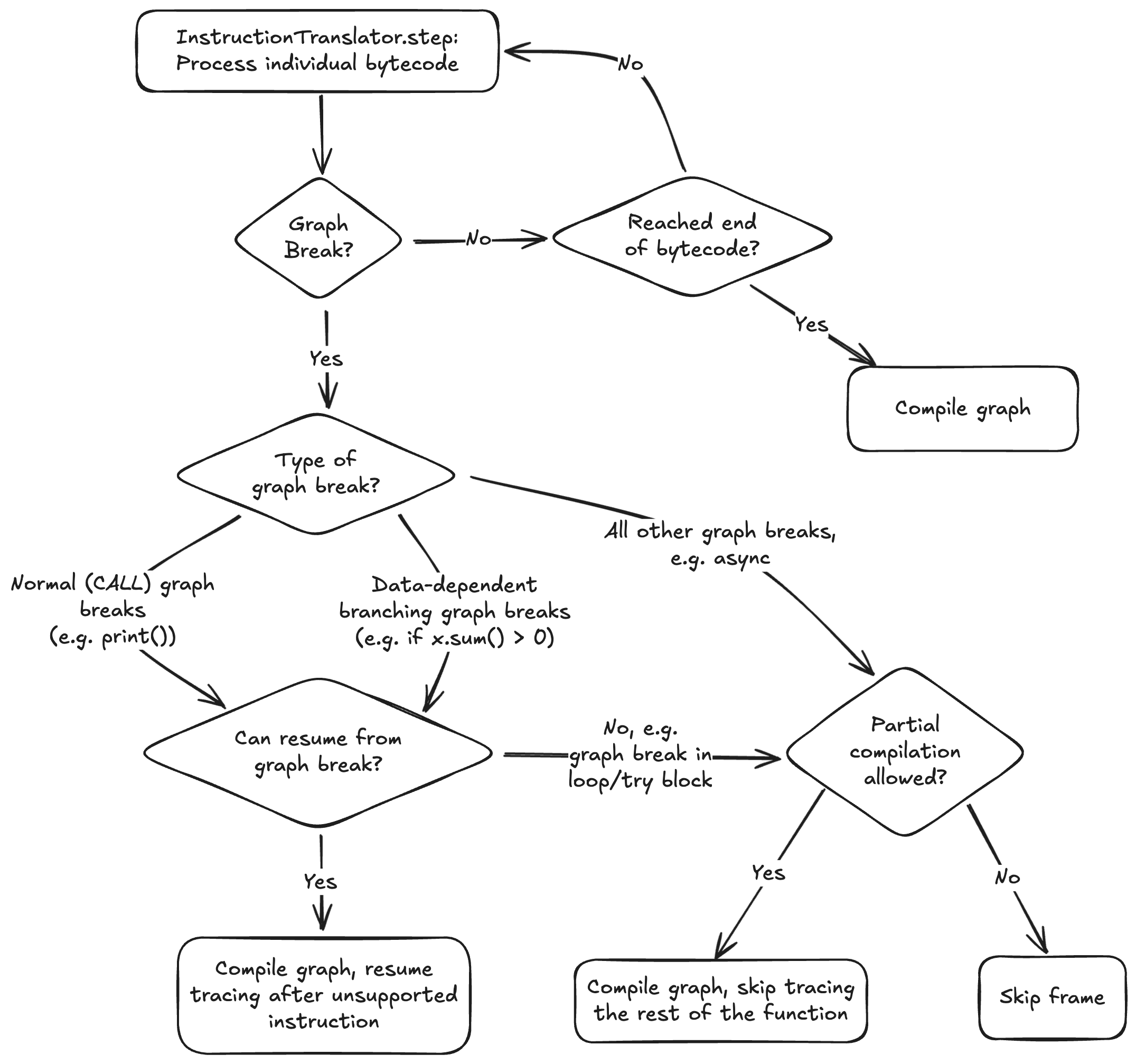
In the course of implementing nested graph breaks, we determined that there were multiple different graph break handling sites in symbolic_convert.py that required sufficiently different codegen’ing. In order to ensure that we did not miss any graph break handling cases, we documented symbolic_convert’s graph break handling more carefully:
- Regular (
CALL/break_graph_if_unsupported) graph breaks - most graph breaks fall under here - Data-dependent condition (
POP_JUMP_IF_*/generic_jump) graph breaks - Store-attribute (
STORE_ATTR) graph breaks - we eventually removed this code path in favor of regular graph breaks - Step graph breaks - the “catch all” graph break if regular and data-dependent graph break handling failed to handle the graph break
Below is a diagram summarizing graph break handling:
Codegen’ing side effects and variables of nested frames
During planning, we had concerns about how side effects and variables (locals, cells, and globals) in nested frames would be codegen’d. For example, we weren’t sure if it was possible to reconstruct a nested frame’s stack values in every case.
Upon further investigation, we found that Dynamo already handles these cases well:
- Sources are constructed with respect to the root frame
- Created cells in nested frames are already constructed properly
- References to cells and globals in nested frames are generated properly
- Locals, cells, and globals are laid out in the same way for root frames and nested frames - so we do not need to handle these 2 cases separately
So codegen’ing side effects and nested variables was essentially complete. Ryan’s work on streamlining side effects and closure handling in H2 ‘24 was particularly helpful.
Top-frame resume assumptions
Since Dynamo previously only supported resuming from graph breaks at the top-level frame, a few features relied on this implementation detail. For example, if there is a graph break in activation checkpointing, we fallback the entire op to eager. This was implemented in the past by:
- Skipping the tracing of a top level frame if its definition file is where activation checkpointing is defined (skips tracing the activation checkpointing mechanism)
- Skipping the tracing of a top level frame if activation checkpointing is active (skips tracing the function we are checkpointing)
Here, the skipping mechanism implicitly relied on the fact that Dynamo could only resume at the top-level frame. When we implemented nested graph breaks, we encountered issues because we attempted to resume inside the activation checkpointing op. The fix was to disallow nested graph breaks inside activation checkpointing and to resume at the frame calling the op.
Other cases where top-frame resume assumptions were made include:
- Functorch ops such as
vmap - Custom
__setattr__methods - Generators
Because it is difficult to exhaustively search for all places in Dynamo where the top-frame resume assumption is made, we added the torch._dynamo.disable_nested_graph_breaks decorator, which allows users to unblock themselves from nested graph break issues by temporarily disabling them in a region of code.
Step graph breaks
Sometimes, when handling a graph break, we compile the ops we have traced so far but skip tracing the rest of the frame. This happens, for example, if we graph break in a try block, or if we encounter a bytecode instruction we don’t support.
Before, we did not need to generate a resume function since we would directly append the original code object to the end of the compiled function and jump to the resume instruction. This works since Dynamo does not trace into compiled functions. But in the case of nested graph breaks, we need to call the resume functions of the upper functions after running the rest of the leaf function.
The clean solution was for the compiled function to call the leaf function’s resume function, which is marked as skipped; then to call the rest of the resume functions as in the regular case of nested resumption. PR
# Non nested step graph break (previous)
def compiled_f(<original f args>):
graph_args = <compute graph args from args>
graph_out = compiled_graph(graph_args)
# NOTE: no stack codegen'd since step graph breaks can only happen on empty stack!
<codegen and store locals>
<codegen side effects>
<load locals>
<jump to unsupported instruction>
<original f code>
# Nested step graph break (new)
def compiled_f_nested(<original frame 1 args>):
graph_args = <compute graph args from args>
graph_out = compiled_graph(graph_args)
values = []
<codegen stack + locals values for all frames>
<codegen side effects>
resume_n = <codegen resume for frame N (step graph break)>
# NOTE: resume_n is NOT traced by Dynamo and frame N has an empty stack!
resume_n_result = resume_n([], [], frame N locals)
values[1].append(resume_n_result)
values.pop(0)
resumes = []
for frame in frames[:-1]: # from 2nd-to-last frame to root frame
resumes.append(<resume function for frame>)
return resumes[-1](*[resumes[:-1], values[:-1], *values[-1]])
# same as before
def resume_function(resumes, values, *(stack + locals)):
<store locals>
<load stack>
if resumes:
result = resumes[-1](*[resumes[:-1], values[:-1], *values[-1]])
<load result to stack>
<jump to resume instruction>
<original code>
Tail-call optimization
Previously, if the top-level frame returns immediately after the graph break, we would skip generating the resume function and immediately return. In the case of nested graph breaks, we can extend this to skip generating resume functions for frames that will immediately return. The main challenge here was correct manipulation of the frames’ stack and locals data.
Current Status and Next Steps
Today, you can enable Dynamo’s nested graph break behavior by setting torch._dynamo.config.nested_graph_breaks = True. Nested graph breaks works on many code examples that we wrote, and we expect nested graph breaks to work on a majority of models, but we are NOT yet considering this to be feature complete as we still need to iron out a number of bugs.
However, we were able to run 2 benchmark models locally: detectron2_fcos_r_50_fpn and speech_transformer (with command python benchmarks/dynamo/torchbench.py --inference --backend=inductor --performance --cold-start-latency --only <model-name>). We picked these models since they had a number of existing graph breaks. The results from benchmarking are:
| Model | detectron2_fcos_r_50_fpn | speech_transformer |
|---|---|---|
| Total graph breaks | 18 → 9 | 9 → 2 |
| Speedup over eager (absolute latency) | 1.38x → 1.42x | 2.47x → 2.53x |
| Compile time | 41s → 38s | 18s → 19s |
So we can see that proper handling of nested graph breaks results in a significant decrease in the total number of graph breaks, and a slight improvement to performance as we are able to capture larger partial graphs.
We observed a small compile time improvement for detectron2_fcos_r_50_fpn but a small regression for speech_transformer. We were hoping for a more significant compile time improvement, but possible explanations for the lack of improvement include (1) the presence of frame skips, step graph breaks, and fallbacks to eager, and (2) the graph breaks are not deeply nested enough and the inner frames aren’t large enough. (1) could also be preventing further performance improvements.
Fortunately, we are able to show in a pathological case that nested graph breaks significantly improves compile time. On a microbenchmark that has 100 nested frames with 200 ops per frame with 1 graph break in the innermost frame, compile time improves from 504s to 34s with nested graph breaks.
Currently, we are in the process of applying torch._dynamo.config.nested_graph_breaks = True to Dynamo unit tests. This process is revealing some subtle breaks that need to be addressed later. We have converted approximately 50% of the Dynamo unit tests so far.
The steps remaining to feature completion are:
- Turn
torch._dynamo.config.nested_graph_breaks = Truefor the remaining Dynamo tests. - Take a large subset of Dynamo tests and wrap the compiled function in an additional frame, thus forcing every graph break to be nested.
- Take a large subset of Dynamo tests, wrap the compiled function in an additional frame, and intentionally introduce additional graph breaks.
- Set
torch._dynamo.nested_graph_breakstoTrueby default. - Improve performance and compile time.
At each step of testing, we anticipate corner cases that will need to be addressed, so the timeline of completion is difficult to estimate - likely on the order of months.