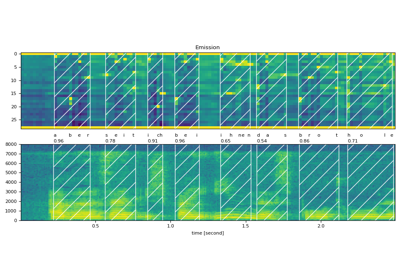
torchaudio.functional.forced_align¶
- torchaudio.functional.forced_align(log_probs: Tensor, targets: Tensor, input_lengths: Optional[Tensor] = None, target_lengths: Optional[Tensor] = None, blank: int = 0) Tuple[Tensor, Tensor][source]¶
DEPRECATED
Warning
This function has been deprecated. It will be removed from 2.9 release. This deprecation is part of a large refactoring effort to transition TorchAudio into a maintenance phase. Please see https://github.com/pytorch/audio/issues/3902 for more information.
Align a CTC label sequence to an emission.


- Parameters
log_probs (Tensor) – log probability of CTC emission output. Tensor of shape (B, T, C). where B is the batch size, T is the input length, C is the number of characters in alphabet including blank.
targets (Tensor) – Target sequence. Tensor of shape (B, L), where L is the target length.
input_lengths (Tensor or None, optional) – Lengths of the inputs (max value must each be <= T). 1-D Tensor of shape (B,).
target_lengths (Tensor or None, optional) – Lengths of the targets. 1-D Tensor of shape (B,).
blank_id (int, optional) – The index of blank symbol in CTC emission. (Default: 0)
- Returns
Tensor: Label for each time step in the alignment path computed using forced alignment.
Tensor: Log probability scores of the labels for each time step.
- Return type
Tuple(Tensor, Tensor)
Note
The sequence length of log_probs must satisfy:
\[L_{\text{log\_probs}} \ge L_{\text{label}} + N_{\text{repeat}}\]where \(N_{\text{repeat}}\) is the number of consecutively repeated tokens. For example, in str “aabbc”, the number of repeats are 2.
Note
The current version only supports
batch_size==1.- Tutorials using
forced_align: